Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Migrating from Rev.ai to Gladia: what global teams should know
TL;DR: At 10,000 hours of audio per month, Rev.ai's per-hour billing compounds quickly once you add diarization, translation, and sentiment as separate line items. Language coverage gaps surface silently in production when non-English or accented audio degrades without returning an obvious error. This guide gives you the exact API payload mappings, WebSocket transition logic, and a TCO model at realistic scale to make a defensible evaluation of switching. If you decide to migrate, our all-inclusive per-hour pricing bundles every audio intelligence feature at the base rate, and most teams complete the endpoint transition and initial production validation in under 24 hours.
Switching your speech-to-text provider: A migration checklist for note-takers and contact center platforms
TL;DR: Switching your speech-to-text provider is a structural risk only if you skip the pre-migration audit. The real danger is not the cutover itself but continuing to run infrastructure that corrupts CRM entries, breaks LLM summaries, and inflates your per-hour cost with add-on fees you never modeled at scale. The four-stage phased cutover in this guide is designed to reach 100% production traffic without user-visible downtime, the same structural approach that let Aircall cut processing time by 95% and scale to over one million calls per week after adopting Gladia.
How decision intelligence improves customer service consistency in contact centers
TL;DR: Contact centers fail to deliver consistent service when routing infrastructure runs on static rules engines that cannot handle the complexity of real human conversation. Modern speech-to-text infrastructure addresses this by processing raw audio and feeding structured outputs to your CRM, using machine learning to analyze intent, sentiment, and speaker characteristics. Transcription accuracy sets the ceiling for every downstream action: a wrong word silently corrupts a CRM entry, a missed intent misfires a routing decision, and a misread sentiment score delays escalation. This playbook covers how to build and deploy that architecture without blowing your latency budget or your unit economics.
Automatic Speech Recognition (ASR): How speech-to-text models work—and which One to Use
Published on Jan 27, 2026
By Anna Jelezovskaia
Automatic speech recognition (ASR), aka speech-to-text (STT) technology, is a constantly evolving field. Knowing which ASR model is right for your product or service can be challenging. CTC, encoder-decoder, transducer, and speech LLMs—each with distinct tradeoffs. What does it all mean? And what do you choose?!
In late 2025, Bruno Hays, Speech Engineering Lead at Gladia, presented an analysis of the ASR architecture landscape to guide the company's selection of its next-generation speech recognition model.
This article, based on Bruno’s research and findings, demystifies all things ASR, giving you detailed and reliable information about speech recognition and ASR architecture to help you make an informed decision on which architecture is best for you, your product, and your business.
Table of contents:
What is ASR? The Basics
Modern ASR Models
Current ASR Model Design
The 5 Primary Modern Architecture Models
Leaders Board: Popular Architecture Models
How to select the right ASR model?
What is ASR? The Basics
ASR stands for Automatic Speech Recognition—a technology that intelligently recognizes human speech and converts it into written text. It’s the foundation behind voice assistants, transcription tools, and real-time communication solutions.
When incorporating speech recognition technologies into your business and customer workflows, the more you know, the better you’ll be able to select an ASR model that’s right for your specific requirements.
So let’s start with some key terminology. These are fundamental terms we use when discussing ASR Models.
Text tokens
Text tokens are slices of sentences created by cutting text at a character, word, or sub-word level using algorithms like BPE (Byte Pair Encoding).
BPE segments words at meaningful boundaries (such as separating prefixes and suffixes), making it more efficient than character-level tokenization.
Embeddings
Embeddings are vectors representing concepts—while humans use words, these are the language of the model.
Textual embedding tables serve as dictionaries to translate tokens into embeddings that models can understand.
Embeddings start as random vectors at the beginning of training and get optimized to store useful information during the training process.
Attention mechanism
Attention is a method for handling sequential data like text or audio by processing each token separately while adding contextual information.
Each token passes through multiple encoder blocks, where it gets refined using context from previous tokens.
The refinement process goes like this: first, the input embedding derived from the embedding table has no context. Then each encoder block adds contextual information, creating progressively better embeddings.
This process not only increases resolution, but the model augments the vector, effectively 'sculpting' a generic token into a highly specialized representation of that word within its specific environment.
Stacking multiple encoder blocks creates higher-level concepts at each step—early blocks might identify word relationships, later blocks might identify sentiment or task-specific features.
Encoders are the "ears" of ASR models that transform raw audio waveforms into meaningful sequences of embeddings for the ASR task.
Most encoders use Transformer architecture based on the attention mechanism.
Audio doesn't need an embedding table like text does because spectrograms already provide vectors—slices of spectrograms can be used directly as embeddings.
Conceptually, encoder output might represent phonemes (like "sh" or "t" sounds) rather than raw audio slices.
Legacy ASR systems first appeared on the scene in the 1970s. Early models had poor ASR performance due to inadequate adapters connecting the audio encoder to the LM.
Modern ASR models take a disruptive approach to speech processing with end-to-end deep learning. Formally working independently: language, acoustic, and lexicon models can now be trained together. Therefore, they function as a single neural network, as opposed to multiple models in previous legacy systems.
The big wins for these improvements are:
Reduces development time and costs.
Achieves unparalleled accuracy levels and supports multiple languages owing to its advanced neural architecture.
Minimizes latency and drastically improves performance and accuracy.
Current ASR Model Design
All modern ASR architecture models have two components that need to work in harmony to succeed:
👂An encoder to understand audio (the "ears").
🧠A language model to produce sensible text (the "brain").
Conceptually, the encoder turns the raw audio into a sequence of phoneme-like embeddings. For example “maaaï neme iz bonde”. The Language model, in theory, converts it into a coherent sentence: “My name is Bond.”
When comparing different model architectures, the key difference is how the encoder and language model interact with each other.
The 5 Primary Modern Architecture Models
There are five main ASR architecture families: encoder-decoder (Whisper, Canary), CTC (Wave2Vec2), encoder-transducer (Parakeet TDT), speech LLMs with continuous input (Voxtral), and speech LLMs with discrete input (GPT-4O, Moshi).
Here we break down each:
Encoder - Decoder
Encoder-decoder models like Whisper use a separate decoder model to generate text token by token.
The decoder uses self-attention to see previously generated tokens and cross-attention to access audio information from the encoder.
Each generated token benefits from language modeling (seeing the start of the sentence) while being grounded in audio through cross-attention.
CTC architecture
CTC forces the encoder to output letters or tokens directly from each audio slice, using an alignment trick that allows repeated letters.
For each audio slice, the encoder outputs a probability distribution over the vocabulary (e.g., 80% chance of T, 15% P, 5% S).
Greedy decoding takes the highest probability letter for each slice, but performs poorly without language modeling.
Adding a language model re-ranks proposed letters by likelihood, significantly improving accuracy.
Beam search allows the language model to effectively "see the future" by keeping multiple possible paths in memory.
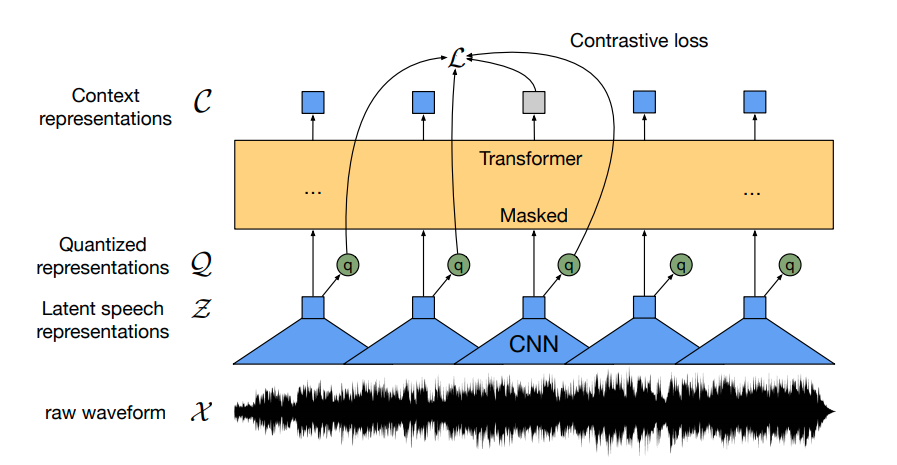
Wave2Vec2 is a family of audio encoder models that is widely used with CTC decoding.
Encoder-transducer
Best described as a "disk and read head" system where the encoder output is the disk and the joiner is the reading head.
The joiner reads encoder embeddings one by one, asks the language model (called "projector") what word should be output, then outputs a token or nothing before moving to the next embedding.
Transducers are streamable by design, but harder to batch effectively.
Parakeet TDT is an example of transducer architecture with an optimization to make decoding much faster.
Speech LLMs with continuous input
Speech LLMs add "ears" (audio encoder) to pre-trained text LLMs that already have strong language modeling capabilities (the "brain").
The pipeline uses a pre-trained encoder (like Whisper's encoder) and a pre-trained LLM (like Gemma), connected by a trainable adapter.
The adapter transforms audio embeddings into word-like embeddings that the LLM can understand—the LLM doesn't have to learn how to process audio..
Examples include Voxtral by Mistral and Qwen Audio.
Output depends on training and prompting—can provide transcription, topic analysis, emotion detection, or other audio understanding tasks.
Speech LLMs with discrete input
Discrete audio tokens are compressed numerical representations of audio that enable audio to be processed and generated as text by the LLM. They are the most effective and popular method used to create speech-to-speech LLMs that need to both understand and generate audio.
The LLM can output interlaced text tokens and speech tokens, with speech tokens decoded into actual sound via a speech decoder.
Examples include GPT-4O (probably), Moshi, and Kimi Audio.
Advantages and Disadvantages
When weighing up the pros and cons, Bruno makes a strong argument in his findings that speech LLMs and encoder-decoders are fundamentally the same mathematically, and therefore provide similar results.
Encoder-decoders use cross-attention for audio access while speech LLMs use self-attention, but both approaches are mathematically equivalent. In practice, both reach very similar ASR performance on leaderboards.
However, the real difference is the training approach:
Encoder-decoders train the encoder and decoder together on audio data.
Speech LLMs train them separately, then teach them to work together.
Leaders Board: Popular Architecture Models
It’s important to stress that there is no one-size-fits-all answer to which architecture model you should use. However, based on Bruno’s findings, we introduce the most popular Model families at the top of the ASR Architecture leaderboard. We spotlight the functionality and highlights of each, so you can make an informed decision on what is best for your needs.
Wav2Vec2
About
Wave2Vec2 was the go-to ASR model from 2020 to 2022 before Whisper, developed by Facebook in 2020.
The model applies BERT's masked language modelling approach to audio—removing audio slices and training the model to predict what's missing. This creates a smart encoder that can be fine-tuned for ASR, for example, by adding a CTC decoding head.
A smart encoder that can be fine-tuned for ASR by adding a CTC decoding head.
Follow-up models, Hubert and WaveLM, added impressive upgrades and improvements. And in mid-November 2025, Facebook released an omnilingual Wave2Vec2 model supporting around 2,000 languages.
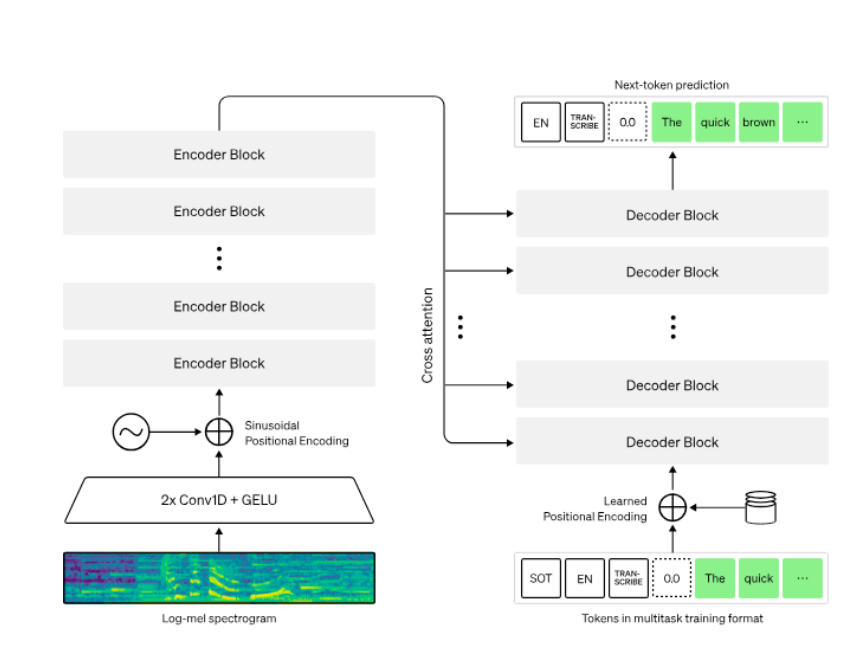
Whisper
About
Developed late 2022 by OpenAI.
A standard encoder-decoder, Whisper is a family of encoder-decoder models released by OpenAI in 2022.
The architecture itself was seen as standard/vanilla at release—the real innovation was proving encoder-decoder models can train on much noisier data than CTC.
Encoder-decoder handles non-standardized text (like "$" for dollars) well because the encoder and decoder aren't as tightly coupled. This makes data creation considerably easier—the same effort that cleaned 1,000hours for CTC can now get 1 million hours for encoder-decoder.
The main innovation resides in proving at scale that encoder-decoder models can be trained on noisier labels. Makes data curation considerably easier.
OpenAI scrapped YouTube and trained Whisper on 700,000 hours of audio with human subtitles, achieving much better performance than alternatives at the time.
Much more robust than any alternative at the time, with multilingual and translation capabilities.
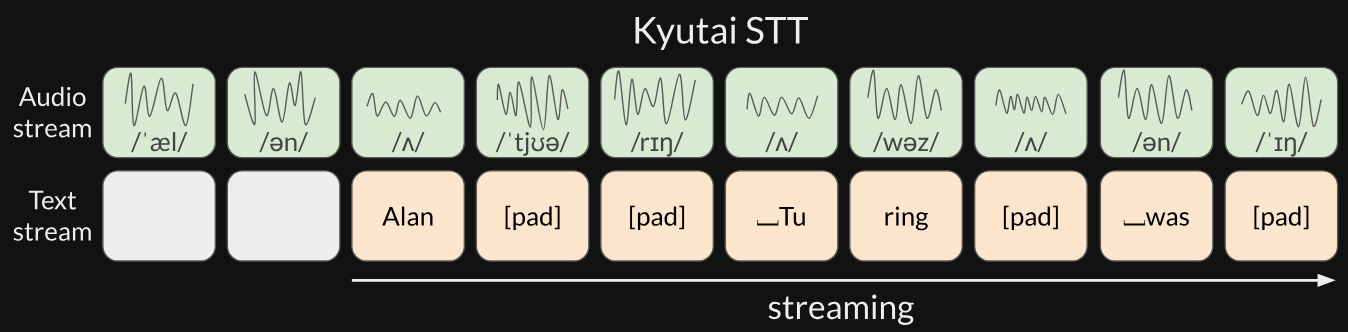
Kyutai-STT
About
Developed in 2025 by Kyutai. The main innovation is a technique called delayed streams modeling—an audio LLM built for real-time seamless interaction.
Traditionally, Voice Assistants have to wait for a full sentence to be finished before they can accurately understand the context and start speaking, which creates awkward pauses. Delayed streams modeling solves this by processing audio and textual data in parallel, but with a slight "delay". This allows the model to "peek" when the incoming information arrives, giving it enough context to begin generating a high-quality voice or text without needing the entire message upfront.
After Moshi, Kyutai’s Voice Assistant, they used this method to build an ASR model family: the Kyutai-STT.
Image source: Kyutai Blog
Highlights
Handles 400 concurrent real-time streams on an H100, it’s streamable and batchable by design, and supports text-to-speech.
The 1b model also features semantic VAD with no delay. This decreases end-of-turn delay to as low as 0.125s with the “flush trick”. The trick forces the model to spit out what it's holding in its buffer rather than waiting for more context.
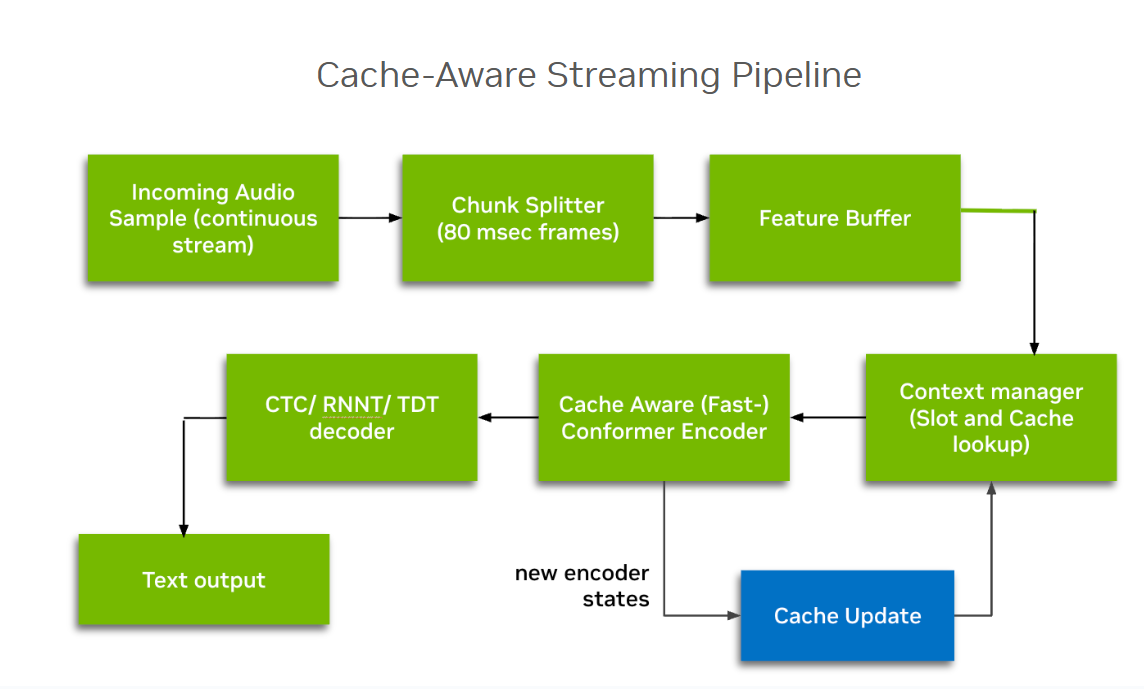
Nemotron-Speech-Streaming-En-0.6B
About
Developed by NVIDIA in 2026, this English-only encoder-transducer model features a unique architectural twist: a Cache-Aware FastConformer encoder. Unlike standard models, this encoder processes audio in a streaming, frame-by-frame manner, eliminating the need to recompute data for each new frame.
When coupled with its inherently streamable Transducer decoder, the result is an ASR model capable of transcribing audio in real time with minimal latency.
The model offers dynamic runtime flexibility, allowing users to adjust the "latency-accuracy" trade-off at inference time without re-training. It supports configurable chunk sizes as low as 80ms or 160ms for near-instant interaction, up to 1.12s for maximum accuracy.
Because it avoids redundant computations, it scales efficiently for production, supporting a high volume of concurrent streams.
How to select the right ASR model?
We’ve put together a few decisive factors you should consider to help you in the selection process.
Word error rate: The ideal goal of any voice recognition application is to achieve zero error rates. However, practical considerations dictate variations beyond our control, so make sure you factor in the precision and accuracy you need in your system when selecting an ASR model. If your application needs uncompromising performance, choose a modern ASR system like Whisper Seq2Seq.
End goal: Consider the requirements of your end users when choosing a model. How will they use the product or service?
Input audio type: Factor in how varied your input audio will be and the languages and dialects the model will need to support.
Performance: Every model performs differently, so you’ll need to evaluate it based on your specific benchmarks. If you need real-time speech-to-text conversions (such as in smart devices and wearables), choose a model with the lowest latency possible.
Conclusion
When choosing an ASR Model for your specific needs, there is no one stand-out that is better than the other. No single "best" architecture—each has distinct tradeoffs for speed, accuracy, data requirements, and streaming capability.
Modern ASR models are increasingly complex and can handle diverse input types, including multiple languages. A simplified end-to-end deep learning model ensures minimal latency, superior accuracy, and high scalability. While delayed stream modeling offers compelling advantages.
Automatic speech recognition plays a pivotal role in numerous business applications, and knowing which kind of ASR system to use for a niche use case can greatly improve end-user experience. When choosing an ASR model for your business, consider all your options. Gladia will be keeping a close eye on innovations and updating our readers regularly.
Bonus Content
Why Speech LLMs evaluation is flawed: https://arxiv.org/pdf/2505.22251
Contact us
Your request has been registered
A problem occurred while submitting the form.
Read more
Speech-To-Text
Migrating from Rev.ai to Gladia: what global teams should know
Speech-To-Text
Switching your speech-to-text provider: a migration checklist for note-takers and CCaaS
Speech-To-Text
How decision intelligence improves customer service consistency in contact centers
From audio to knowledge
Subscribe to receive latest news, product updates and curated AI content.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.