Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Speech-to-text for AI medical scribes: Why clinical vocabulary breaks generic STT
TL;DR: Generic STT engines fail in clinical environments because language model probability overrides correct acoustic detection of medical terms, substituting phonetically plausible but clinically wrong candidates silently. The result corrupts drug names, dosages, and diagnoses before the LLM ever sees them. Before selecting an STT engine for a medical scribe, verify four things: whether vocabulary biasing works at inference time without fine-tuning, whether async diarization accurately separates clinician and patient audio, whether the model holds up on noisy consultation recordings rather than clean read-speech, and whether the vendor's data training policy covers PHI by default on your plan.
Migrating from self-hosted Whisper to a managed speech-to-text API
TL;DR: Self-hosting Whisper's true cost rarely sits in the model weights. GPU idle time, VRAM leaks under parallel load, and the engineering hours spent maintaining CUDA dependencies and diarization pipelines are where the bill compounds. For teams processing under roughly 3,000 hours per month, assuming 20% of one US FTE at $150K loaded annual cost, a managed API is cheaper, though the break-even shifts materially against your actual labor cost. Above that threshold, the decision depends on your DevOps overhead and whether audio accuracy on real-world recordings matters for downstream systems like CRM sync and coaching scores.
Migrating from AssemblyAI to Gladia: A step-by-step switching guide
TL;DR: Switching from AssemblyAI requires four concrete changes: update one auth header, remap batch endpoints, adjust the JSON response schema, and resample audio for WebSocket connections. Multiple customers independently report completing these in under a day with a rollback abstraction layer in place. The bigger structural difference is cost model: a production stack with diarization, sentiment, entities, and summarization runs $0.30/hr on AssemblyAI's Universal-2 tier because each feature is metered separately, versus a bundled base rate. This guide covers the exact parameter mappings, payload diffs, WebSocket reconfiguration, and a zero-downtime cutover strategy.
Live transcription made simple with Twilio, Python & Gladia
Published on July 15, 2025
Live voice AI is no longer a concept of the future. From customer support to smart IVR (Interactive Voice Response) systems, speech is now transcribed in real time—often before the speaker finishes a sentence.
Live voice AI is no longer a concept of the future. From customer support to smart IVR (Interactive Voice Response) systems, speech is now transcribed in real time—often before the speaker finishes a sentence.
To actually feel instant, responses must happen within 280 milliseconds or shorter—the human threshold for “real-time.” This requires capturing, streaming, decoding, and processing audio near-instantly.
In 2025, that’s finally possible. Better streaming protocols, lightweight models, and scalable infrastructure have made sub-300ms AI responses both practical and reliable. Done right, it feels smooth and natural, you forget you’re speaking to a machine.
Which is just what Twilio users want. And thanks to Gladia Solaria RT, it’s easy to achieve.
Solaria natively supports Twilio’s 8-bit, 8 kHz μ-law audio, eliminating the need to decode or convert it. While most STT tools buffer several seconds of audio, Solaria streams and transcribes live, returning evolving partial transcripts as you speak.
This streaming-first design keeps latency low and interactions fluid. It’s how Solaria delivers the speed and simplicity most general-purpose models can’t.
In this guide, you’ll learn how to connect Twilio Voice Media Streams to Gladia API using Flask, and deploy a production-ready proxy. Ideal for developers who value speed, simplicity, and real-time results.
Why real-time call transcription matters to the business
Today, customer expectations are higher than ever, and every second on a call counts. Real-time transcription isn’t just a cool feature; it’s a competitive advantage that directly impacts team performance, customer experience, and business efficiency.
Real-time transcription creates practical value across key parts of the customer call experience.
Shorter handle times mean happier callers
When service agents can follow a transcript as the caller speaks, they don’t have to constantly ask for clarification or take long pauses to jot down notes. This naturally reduces the average handle time (AHT), resulting in quicker resolutions and a smoother experience.
Customers get off the call faster, and agents are ready for the next one without burnout.
Live text triggers on-screen prompts while the customer is still talking
Imagine a help desk tool that starts suggesting solutions mid-sentence. With real-time transcription feeding text into your backend, your systems can recognize keywords and immediately display relevant knowledge base articles or troubleshooting scripts, before the caller even finishes explaining the issue.
Instant PCI and PII checks spot problems before they become liabilities
When sensitive information, such as credit card numbers or personal identifiers, is spoken aloud, real-time transcription lets AI instantly flag this. Your systems can mask or redact the data on the fly, keeping your business in compliance with PCI (Payment Card Industry) and PII (Personally Identifiable Information) regulations without manual intervention.
Accurate call notes drop straight into the CRM without extra typing
Forget typing up notes after every call. Real-time transcription lets you automatically generate clean, structured summaries that push directly into your CRM. That means less administrative work, better record-keeping, and more time spent solving customer problems—rather than documenting them.
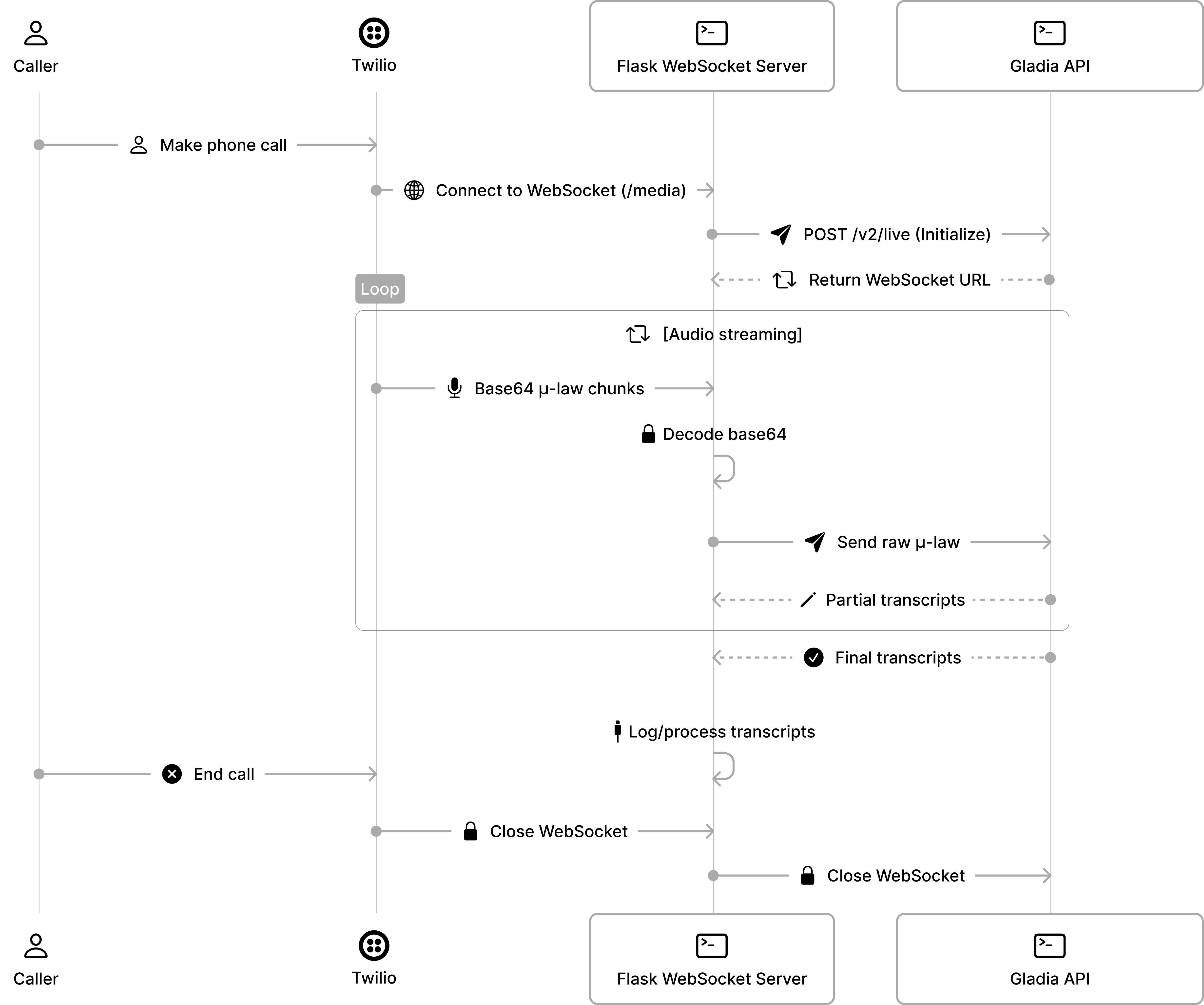
Architecture: How data flows through the system
A seamless, live voice AI experience requires a system carefully tuned for speed, clarity, and minimal friction. Let’s walk through how Gladia Solaria fits naturally into your voice stack, and why those technical choices make a real difference.
At a high level, the architecture is refreshingly simple, yet incredibly powerful. Here’s the flow:
When a user calls, Twilio captures and streams the audio in real time to your WebSocket proxy. That proxy does the light lifting, decoding base64 audio chunks, and forwarding them directly to Gladia.
Gladia processes the raw audio and returns live transcripts (including partials and final utterances) in milliseconds. Each piece fits together to deliver a real-time loop that feels instant to the caller.
That’s the difference between voice AI that feels reactive and one that feels human.
Why native μ-law support matters
Here’s where Gladia Solaria shines. When you make a call using Twilio, it streams the voice audio in 8 kHz, 8-bit μ-law format. Let’s unpack what that means:
μ-law (pronounced “mu-law”) is a type of audio compression commonly used in telephony. It reduces the size of audio data while preserving the clarity of human speech by encoding quiet sounds with greater precision than louder ones. This is especially useful for conversations.
8 kHz means the audio is sampled 8,000 times per second, which is the standard for phone calls.
8-bit means that each audio sample is stored using 8 bits (1 byte), which keeps file sizes small.
VoIP (Voice over Internet Protocol) is a technology that lets you make phone calls over the internet rather than through traditional phone lines. Twilio uses VoIP to handle calls and stream audio in real time.
Most speech-to-text (STT) engines can’t use this μ-law audio directly. They require you to convert or resample it first. And this extra step adds CPU usage, latency, and complexity.
A quick latency breakdown
So, what does “real-time” really mean in practice? From caller to transcript, here’s a rough breakdown of the latency involved:
Twilio to proxy: ~20–40 ms
Proxy processing & forwarding: ~5–10 ms
Gladia transcription & response: ~150–200 ms
Add it all up, and your round-trip stays comfortably below the critical 300 ms threshold. This makes it feel truly conversational, responses arrive before users even realize there's a delay.
And these numbers aren’t just academic; they shape user perception. In contact centers, slow or stilted voice bots feel robotic, frustrate users, and erode trust. But when the response loop is tight—under 300 ms—the conversation feels natural, even effortless.
It’s the difference between a caller waiting on the system versus a system that’s waiting on the caller.
That kind of responsiveness opens the door to more than just transcription. You can stack real-time NLU (Natural Language Understanding) intent detection, or agent assist on top, because when latency is low, you’ve got headroom.
You’re not just keeping up with the call, you’re staying one step ahead.
What you need: The quick-start checklist
Ensure you have the following key components ready:
Gladia API keys
A Twilio number with Media Streams enabled
A Python environment
And that’s all you need.
[If you’d rather dive into the implementation and skip the setup, the code is available on the GitHub repository.]
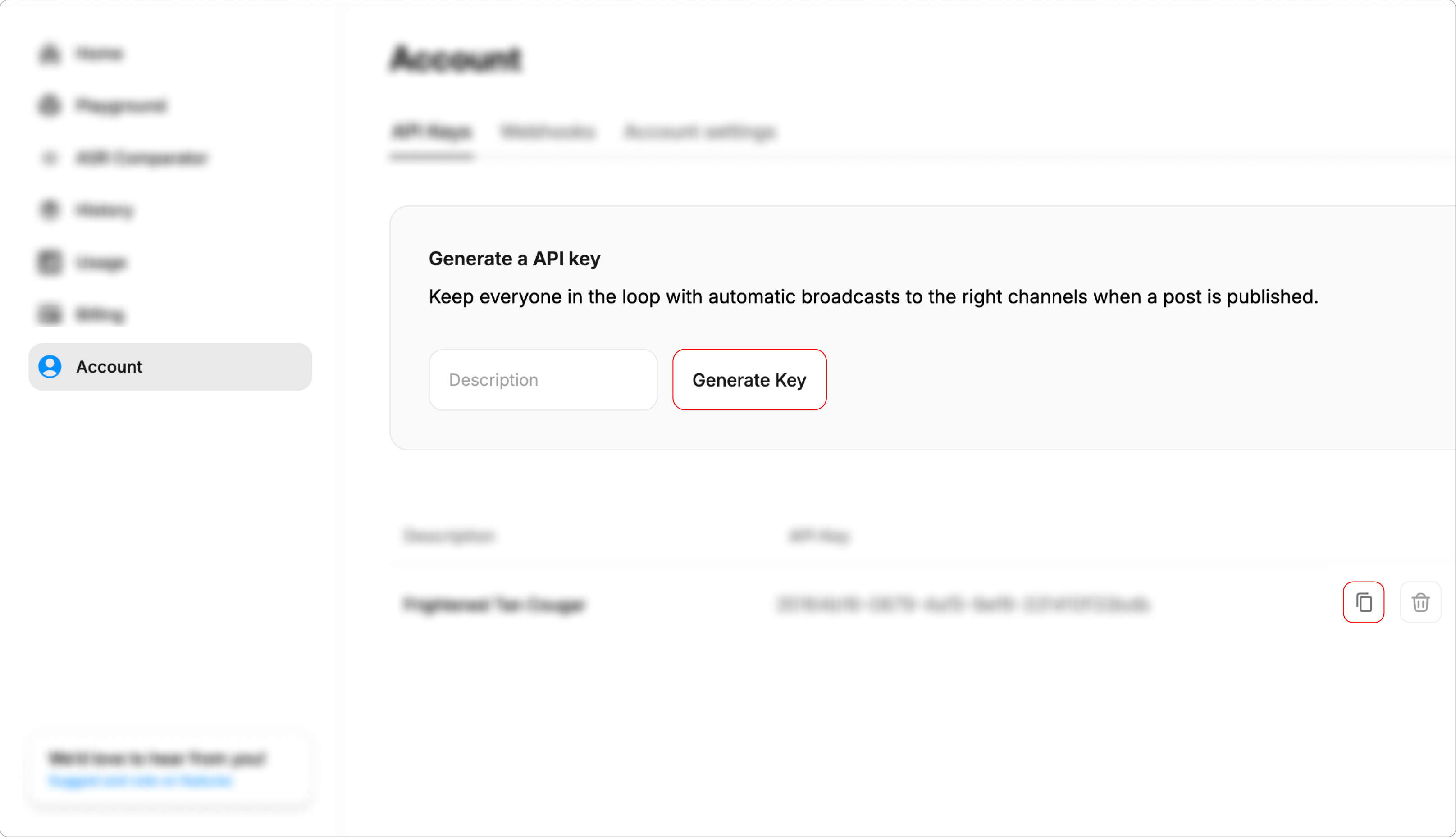
Gladia API key
Sign in to Gladia and copy the API key from your dashboard:
With this, you’re cleared to set up STT.
Twilio account setup
Log in or create an account. Note your Account SID, Auth Tokens, and number.
Buy or port a voice-enabled number.
Switch on Media Streams (single-track, mono) in the Voice settings.
Python virtual environment & Install libraries
To get started, clone the Gladia samples repository and switch to the relevant branch. Then, create a virtual environment to keep your dependencies clean and isolated.
In your project directory, create the file and name it .env:
Install all libraries:
Set up a secure tunnel for local testing (Ngrok)
Start the server:
Expose your server publicly:
Update your TwiML:
Update the URL in your TwiML to your ngrok URL (e.g., wss://jl.mydomain.com/media or the ngrok random URL previously attributed by ngrok)
Test:
Call your Twilio number.
You should see transcripts appearing in your console.
How to build your voice AI workflow
We’ve just set up a real-time transcription pipeline using Twilio and Gladia. Whether you’re prototyping or gearing up for production, the following components form the foundation of a fast, reliable voice AI workflow.
Spin up a live Gladia session
Before you can start streaming audio, you'll need to spin up a live Gladia session. This session will act as the WebSocket endpoint that receives μ-law encoded audio from your proxy and responds with real-time transcriptions.
Here’s a quick Python script using requests to initialize a session:
When successful, it returns a WebSocket URL that you can use to forward audio in real-time. This URL becomes the core of your transcription pipeline. You only need to create one per call session.
Write a Flask WebSocket proxy
Once your Gladia session is live, the next step is to build a proxy to bridge Twilio and Gladia. This small Flask app listens for incoming audio from Twilio, decodes it, and streams it straight to Gladia’s transcription service, all in real-time.
Because Gladia natively supports the μ-law audio format used by Twilio, you don’t need to use extra decoding tools such as audioop (a standard Python library used to manipulate raw audio data; typically required when converting or resampling audio formats).
We handle the audio as is, making the setup simpler and more efficient.
Create a TwiML Bin to start streaming audio
Now that your proxy is ready to accept live audio, instruct Twilio to start streaming that audio to your WebSocket server. This is done with a small TwiML snippet, Twilio’s XML-based markup for call control.
Let’s quickly break down xml:
<Response> is the container for all TwiML instructions.
<Start> instructs Twilio to start streaming media as soon as the call is connected.
<Stream url="..."> is where you point Twilio to your WebSocket proxy (like the /media route in your Flask app). It must use secure WebSockets (wss://).
<Dial> keeps the call going—streaming continues in the background while the call is connected to this number. You can replace this with other verbs like <Say>, <Gather>, or <Conference>, depending on your use case.
Every time a call reaches this TwiML, Twilio opens a WebSocket connection to your server and sends base64-encoded μ-law audio frames in real time, 20 ms at a time. These get decoded by your proxy and forwarded to Gladia, where live transcription happens on the fly.
Expose locally and make the first test call
With everything wired up, it’s time to run your Flask proxy and expose it so Twilio can reach it. First, make sure all dependencies are installed. Now run your server:
python server.py
By default, this listens on port 5000, but you can change that if needed:
Since Twilio needs to connect to your proxy over the internet, you’ll want to tunnel it, especially during local development. The easiest way? Ngrok:
You can even use a custom domain if you’ve set one up with ngrok:
Once your proxy is publicly accessible, point your Twilio number or app to the TwiML Bin you created earlier (with the <Stream> pointing to your /media WebSocket). Now make a call to your Twilio number and watch the magic happen.
You should see real-time logs like this in your terminal:
That’s it, you’re now streaming audio live, decoding it in real time, and getting clean, accurate transcripts back in milliseconds. Welcome to live voice AI!
Let’s pause and look under the hood. When we say this system operates in under 300 milliseconds, it’s not just bragging.
So, what exactly is happening during that blink of an eye?
It starts the moment the caller speaks. Twilio sends 20 ms μ-law audio chunks to your Flask proxy, which decodes and streams them directly to Gladia; no resampling needed. Gladia begins transcribing instantly, returning partial results within 100–150 ms and final transcripts well before the 300 ms mark.
All of this happens asynchronously in a lightweight Python app that prioritizes speed without sacrificing clarity or accuracy.
How to move from demo to production
Getting real-time transcription working in a demo is impressive, but moving it into production is where things get real. At scale, your architecture needs to be robust, secure, observable, and cost-effective.
That shift from a local test to a production-ready service isn’t just about stability, it’s about foresight. In production, you’re dealing with real users, unpredictable network conditions, concurrent streams, and compliance needs. That means every piece of your stack, from the WebSocket proxy to the Gladia API integration, must be engineered for reliability and flexibility.
Here’s how to level up your Twilio + Gladia setup for real-world use.
Scaling
For production deployments, a simple Flask dev server won’t cut it. Use a production-grade setup, such as Gunicorn paired with Uvicorn workers to handle WebSocket traffic efficiently.
Better yet, containerize the proxy using Docker, allowing it to scale horizontally across services like Kubernetes or ECS.
Security
In production, you’ll want to verify the X-Twilio-Signature header to ensure that incoming WebSocket requests come from Twilio.
Additionally, consider protecting your media endpoint with JWT authentication to prevent unauthorized access, especially if it’s exposed over a public domain.
Observability
Once live, you'll need visibility into how your service is performing. IntegratePrometheus metrics to track request counts, response times, and error rates.
For deeper insights, instrument your code with OpenTelemetry to generate traces across your transcription pipeline. For example, from WebSocket connection to final transcript.
Cost control
Real-time transcription can become expensive if left unmanaged. Usemax idle timeouts to shut down inactive sessions cleanly. And monitorconcurrent WebSocket connectionsto prevent over-provisioning and maintain cloud costs within budget.
Ultimately, moving beyond the demo isn’t just about uptime, it’s about building confidence. In production, every decision, such as how you scale services, secure endpoints, or manage concurrency, can ripple across user experience and operational cost.
The good news? With a modular pipeline like Twilio + Gladia, you can evolve each component independently. Start lightweight, then harden gradually as traffic and complexity grow.
Final Remarks
Real-time transcription using Twilio and Gladiais smooth and efficient. Leveraging Gladia’s native support for μ-law audio, you can skip decoding and resampling altogether and send raw Twiliostreams straight to transcription.
The entire pipeline, from receiving to decoding, forwarding, and transcribing, remains minimal and fast, easily staying under the critical 300 ms latency mark. With a lightweight Flask and WebSocket setup, this solution integrates smoothly into any modern Python backend, making real-time voice AI not only possible but production-ready.
What’s more, the system's modularity—Twilio for capture, Flask for routing, and Gladia for transcription—makes it easy to extend. And with that kind of performance, you're not just building functionality, you’re shaping how users perceive your product.
So now you’re here: Twilio streaming live voice, Gladia returning transcripts in milliseconds, and your backend humming with real-time intelligence.