Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Speech-to-text for AI medical scribes: Why clinical vocabulary breaks generic STT
TL;DR: Generic STT engines fail in clinical environments because language model probability overrides correct acoustic detection of medical terms, substituting phonetically plausible but clinically wrong candidates silently. The result corrupts drug names, dosages, and diagnoses before the LLM ever sees them. Before selecting an STT engine for a medical scribe, verify four things: whether vocabulary biasing works at inference time without fine-tuning, whether async diarization accurately separates clinician and patient audio, whether the model holds up on noisy consultation recordings rather than clean read-speech, and whether the vendor's data training policy covers PHI by default on your plan.
Migrating from self-hosted Whisper to a managed speech-to-text API
TL;DR: Self-hosting Whisper's true cost rarely sits in the model weights. GPU idle time, VRAM leaks under parallel load, and the engineering hours spent maintaining CUDA dependencies and diarization pipelines are where the bill compounds. For teams processing under roughly 3,000 hours per month, assuming 20% of one US FTE at $150K loaded annual cost, a managed API is cheaper, though the break-even shifts materially against your actual labor cost. Above that threshold, the decision depends on your DevOps overhead and whether audio accuracy on real-world recordings matters for downstream systems like CRM sync and coaching scores.
Migrating from AssemblyAI to Gladia: A step-by-step switching guide
TL;DR: Switching from AssemblyAI requires four concrete changes: update one auth header, remap batch endpoints, adjust the JSON response schema, and resample audio for WebSocket connections. Multiple customers independently report completing these in under a day with a rollback abstraction layer in place. The bigger structural difference is cost model: a production stack with diarization, sentiment, entities, and summarization runs $0.30/hr on AssemblyAI's Universal-2 tier because each feature is metered separately, versus a bundled base rate. This guide covers the exact parameter mappings, payload diffs, WebSocket reconfiguration, and a zero-downtime cutover strategy.
Text normalization in speech recognition explained
Published on Mar 19, 2026
By Ani Ghazaryan
Speech recognition systems are good at turning audio into words. But the transcripts they produce aren’t always structured in ways that software can reliably work with.
A raw transcript might look like this:
“the meeting will happen on march third twenty twenty four at ten am”
But most applications expect something closer to:
“The meeting will happen on March 3, 2024 at 10 AM.""
That difference might seem minor, until transcripts start flowing into search indexes, analytics pipelines, or NLP models that expect numbers, dates, and entities in standardized formats. At that point, the gap between how people speak and how software interprets text becomes a real engineering problem.
In this article, we’ll walk through how speech systems handle that gap, where normalization fits into the ASR pipeline, and what developers should understand when building applications on top of speech-to-text APIs.
TL;DR: Text normalization in speech recognition converts spoken language into standardized written text so transcripts are readable and usable by downstream systems. For example, an ASR system may hear “twenty five dollars” but normalize it to “$25”. This step usually happens during post-processing in the ASR pipeline, transforming raw model output into structured text suitable for applications like search, analytics, voice assistants, and meeting transcription. Modern speech-to-text APIs often perform normalization automatically, allowing developers to work with clean transcripts rather than literal spoken output.
What is text normalization?
Text normalization in speech recognition refers to the process of converting the literal words detected by an automatic speech recognition (ASR) model into a standardized written format that aligns with how humans typically write text.
When people speak, they express numbers, dates, abbreviations, and symbols verbally. However, written language often represents those concepts in a condensed form using digits, punctuation, or standardized formats. Text normalization bridges this gap between spoken language and written representation.
Consider how a speech recognition system might initially transcribe speech:
Raw ASR output
“i spent twenty five dollars on lunch yesterday”
While understandable, this format does not match how written text is typically represented. After normalization, the transcript becomes:
Normalized transcript
“I spent $25 on lunch yesterday.”
Normalization improves readability, but more importantly, it ensures consistency so downstream systems can interpret the text correctly.
For many real-world applications, that raw output is difficult to parse, search, or analyze. Text normalization therefore plays a critical role in transforming ASR output into structured, machine-friendly text.
Why text normalization matters in real applications
For developers building systems around speech data, the difference between raw transcripts and normalized text can significantly affect how usable that data becomes.
Speech is inherently informal, redundant, and loosely structured, while most software systems expect structured and consistent text formats. Without normalization, speech transcripts may remain technically correct but difficult for downstream systems to interpret reliably. Several common speech-driven applications illustrate why this transformation matters:
Search and retrieval systems: Search engines and database queries often rely on structured values. When speech is transcribed literally, numeric expressions appear in their spoken form, which can make matching or querying less reliable. Converting phrases such as “five hundred dollars” into numeric representations allows search systems to treat spoken input the same way they treat structured data.
Meeting transcription and documentation: Meeting assistants generate transcripts, summaries, and action items that people read and share. Literal transcripts can feel cluttered because spoken language expands concepts that written language typically compresses. Normalization introduces punctuation, capitalization, and standardized date or number formats, making transcripts easier to scan and interpret.
Voice assistants and conversational interfaces: Voice interfaces frequently convert speech into commands that interact with structured systems such as timers, calendars, or databases. For these interactions to work reliably, spoken quantities must be translated into machine-readable values that backend systems can execute.
Analytics and NLP pipelines: Many speech platforms feed transcripts into downstream natural language processing systems such as:
Named entity recognition
Sentiment analysis
Topic modeling
Keyword extraction
These systems generally operate more reliably when numeric values, dates, and measurements follow standardized formats. Converting spoken forms into normalized representations improves entity detection, reduces ambiguity, and helps maintain consistent data across pipelines.
In practice, text normalization acts as a bridge between conversational speech and structured data systems, ensuring that transcripts are usable both for humans reading them and for software systems processing them.
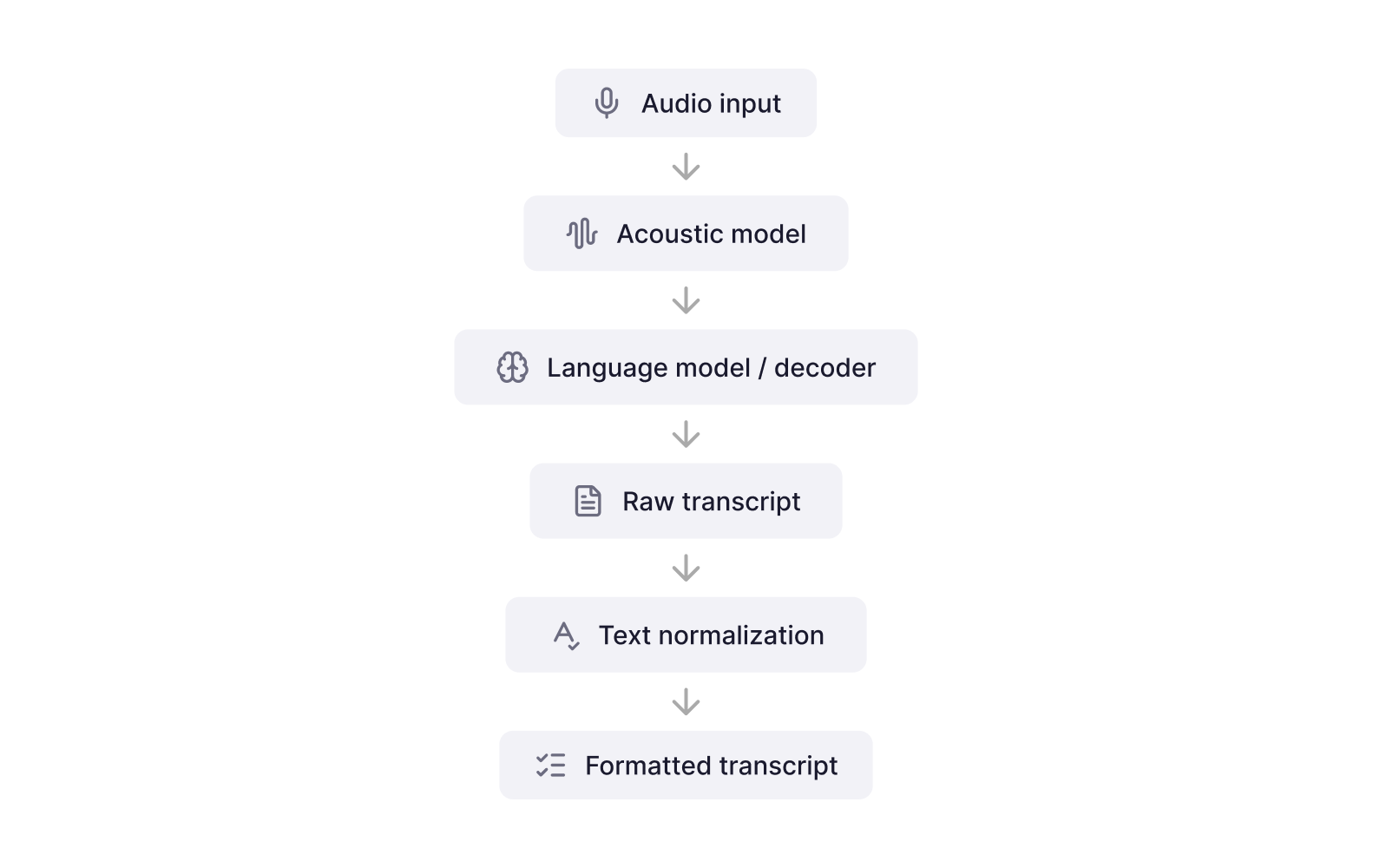
Where text normalization sits in the ASR pipeline
To understand normalization properly, it helps to look at the broader architecture of a speech recognition pipeline. Although implementations vary, most ASR systems follow a similar conceptual flow:
The acoustic model analyzes audio signals and predicts phonetic representations or tokens. In turn, the language model helps determine the most likely word sequence given those predictions. The decoder then produces a textual output representing what the system believes was spoken. However, this output is often literal and close to the spoken form. It may lack punctuation, proper casing, or formatted numbers.
Text normalization therefore operates as a post-processing step, transforming raw ASR output into standardized text. This distinction is important because it highlights the difference between speech recognition preprocessing vs post-processing.
Pre-processing: Speech recognition pre-processing typically includes steps such as:
Audio resampling
Noise reduction
Voice activity detection
Segmentation
These steps prepare the audio before it reaches the recognition model.
Post-processing: Occurs after the transcript is generated. It includes:
Punctuation restoration
Capitalization
Formatting numbers and dates
Expanding or contracting abbreviations
Text normalization
Normalization, therefore sits at the interface between ASR output and downstream applications.
Types of text normalization in speech recognition
Text normalization covers a range of transformations that convert spoken expressions into standardized written formats. While the exact rules vary across languages and domains, several categories appear consistently across speech recognition systems.
Number normalization: Numbers are one of the most common normalization tasks. Spoken numbers often consist of multiple tokens that must be interpreted as a single numeric value.
For example, a transcript may contain:
“one hundred twenty five”
which is normalized to:
125
Decimals require similar interpretation:
“three point five” → 3.5
Number normalization becomes more complex when handling larger values, compound numbers, or context-dependent expressions.
Date normalization: Spoken dates can appear in many linguistic forms and must be converted into standardized written representations.
For example:
“march third twenty twenty four” → March 3, 2024
Similarly:
“the meeting is on july fifteenth” → July 15
Date normalization requires understanding ordinal numbers and resolving ambiguity in how dates are spoken.
Currency normalization: Currencies combine numeric values with units and symbols.
For example:
“twenty five dollars” → $25 “thirty euros” → €30
This transformation allows financial quantities to be represented in formats that downstream systems can interpret consistently.
Measurement normalization: Measurements frequently appear in domains such as logistics, science, and health.
Examples include:
“five kilometers” → 5 km
“twenty two degrees” → 22°
Normalization converts spoken quantities into compact representations using standardized units.
Abbreviation normalization: Certain spoken phrases correspond to abbreviated forms in written language.
For example:
“united states” → U.S.
“doctor smith” → Dr. Smith
This transformation helps transcripts match common written conventions.
Punctuation restoration: Spoken language does not contain explicit punctuation, yet punctuation is essential for readability and sentence structure.
A raw transcript such as:
“i think we should review the proposal tomorrow morning”
becomes:
"I think we should review the proposal tomorrow morning."
Punctuation restoration improves clarity and helps downstream language models interpret sentence boundaries.
Casing: Speech recognition systems frequently output lowercase text. Normalization restores proper capitalization for names, locations, and sentence beginnings.
For example:
“john joined the meeting from paris”
becomes:
"John joined the meeting from Paris."
Formatting: Formatting combines several normalization steps—numbers, currency, punctuation, and casing—to produce readable text.
For example:
“the total is two hundred thirty four dollars and fifty cents” → The total is $234.50
Although each transformation appears straightforward in isolation, normalization becomes significantly more complex when applied across multiple languages, ambiguous phrasing, and real-time transcription systems.
Inverse text normalization
Inverse text normalization (ITN) refers to the specific process of converting spoken representations into structured written forms. While the terms “text normalization” and “inverse text normalization” are sometimes used interchangeably, they describe slightly different concepts depending on context. In many ASR systems, text normalization refers broadly to formatting and standardizing transcripts, while inverse text normalization specifically refers to converting spoken words into structured symbols or digits.
This process is called inverse because it reverses the transformation used in text-to-speech systems. In text-to-speech pipelines, the system may convert “$25” → “twenty five dollars” so the synthesizer can pronounce the text naturally. In speech recognition, the opposite transformation occurs. “twenty five dollars” → “$25.”Inverse text normalization, therefore, sits at the boundary between spoken language and structured written representation.
Challenges in text normalization
At first glance, text normalization might look like a simple formatting step that happens after speech recognition. In reality, it is one of the most difficult parts of building a reliable speech pipeline.
The challenge stems from the nature of spoken language itself. Human speech is ambiguous, context-dependent, and structurally different from written text. A speech recognition model may correctly capture what was said, but converting that output into the correct written representation requires additional interpretation.
Ambiguity and context in spoken language
One of the most fundamental challenges in normalization is that many spoken expressions have multiple valid written representations. Consider the phrase “twenty twenty.”
This sequence could represent several different things depending on context:
2020 — a year
20 20 — two separate numbers
20:20 — a time
20/20 — a visual acuity reference
From the perspective of the ASR model, the audio signal itself does not contain enough information to determine which of these representations is correct. The model simply transcribes the spoken tokens.
Normalization systems therefore need to rely on additional signals, such as surrounding words, sentence structure, or application context, to determine the most appropriate formatting.
For example:
“the year twenty twenty changed everything” → 2020“vision was measured as twenty twenty” → 20/20
Without contextual reasoning, normalization would frequently produce incorrect outputs.
Multilingual normalization
The complexity of normalization increases significantly in multilingual systems.
Different languages express numbers, dates, and quantities using distinct grammatical structures and formatting conventions. Even simple numeric expressions can vary widely across languages. For example:
English: twenty five
French: vingt-cinq
German: fünfundzwanzig (literally “five and twenty”)
Although all three correspond to the number 25, their spoken structure differs considerably. Some languages combine number components in ways that do not align with the final numeric representation.
Beyond numbers, formatting conventions also differ across languages:
Date formats (MM/DD/YYYY vs DD/MM/YYYY)
Decimal separators (period vs comma)
Currency placement and spacing
Measurement conventions
A normalization system operating across languages cannot rely on a single rule set. Instead, it must incorporate language-specific grammars and formatting rules to generate correct written outputs. This is one reason why multilingual speech systems often require dedicated normalization layers per language.
Domain-specific vocabulary
Another layer of complexity arises from domain-specific language. Different industries frequently use specialized terminology, numeric conventions, and measurement formats that influence how speech should be normalized. For example:
Medical transcripts often include dosage information such as “two point five milligrams” or “one hundred twenty over eighty.”
Financial earnings calls contain currency figures, percentages, and financial metrics.
Logistics or manufacturing systems may involve measurements, quantities, and identifiers.
A phrase such as “two point five milligrams” must be normalized carefully depending on context: 2.5 mg in a clinical transcript and 2.5 milligrams in a more formal medical record.
Similarly, phrases like “ten K filing” or “one twenty five basis points” require domain awareness to produce the correct written representation. Handling these cases reliably often requires domain-aware normalization rules or specialized vocabularies that reflect the conventions used in a particular industry.
Rule-based vs ML-based normalization
Historically, many speech systems relied on rule-based normalization. These systems used hand-crafted grammars or regular expressions to detect patterns and apply formatting rules:
Regex rules for number patterns
Grammar systems for dates
Lookup tables for abbreviations
Rule-based systems offer several advantages: They are predictable, interpretable, and relatively easy to control. Developers can define exactly how specific phrases should be transformed. However, rule-based systems struggle with ambiguity and linguistic variation. As speech applications expanded across languages and domains, purely rule-based approaches became difficult to maintain.
ML-based normalization: Machine learning approaches attempt to learn normalization patterns from data. Neural models can map spoken forms directly to normalized representations.These models can generalize across patterns and languages, but they require training data and careful evaluation.
Hybrid approaches: In practice, many production systems combine both approaches. A hybrid system may use:
Rule-based grammars for deterministic patterns
ML models for ambiguous cases
Language models for contextual decisions
This layered design provides both precision and flexibility.
Text normalization in real-time speech applications
In these systems, transcripts must be both accurate and readable while arriving with minimal latency. Consider a meeting assistant generating live transcripts. If the system outputs literal spoken text such as:
“the revenue increased by five hundred thousand dollars”
Developers may want the display to show:
“The revenue increased by $500,000.”
Achieving this transformation while maintaining real-time performance requires efficient normalization algorithms.
In streaming systems, normalization may occur incrementally as new transcript segments arrive. This introduces additional complexity, since the system may not yet have the full sentence context. Balancing latency, accuracy, and readability is therefore a key challenge in real-time speech pipelines.
How speech-to-text APIs handle text normalization
Modern speech-to-text APIs typically incorporate normalization as part of their transcription pipeline. Rather than returning literal spoken output, many systems provide transcripts that are already formatted for readability. Developers may therefore receive output that includes punctuation, capitalization, normalized numbers, and formatted dates.
Many speech recognition APIs, including platforms such as Gladia, handle normalization automatically as part of the transcription process. This allows developers to work with transcripts that resemble natural written text instead of raw spoken forms.
Some APIs may also provide configuration options such as:
Returning raw transcripts
Returning normalized transcripts
Enabling punctuation restoration
Formatting numbers or timestamps
The exact capabilities depend on the provider and implementation. However, most often normalization is integrated into the API pipeline, reducing the need to implement formatting logic manually.
Best practices for developers integrating STT APIs
When building systems that consume speech transcripts, you should think carefully about how normalization interacts with downstream workflows. A few practical considerations can help avoid common issues:
Decide whether to use API normalization: If the speech API already provides normalized transcripts, it may be unnecessary to implement additional formatting layers. However, some applications may require domain-specific formatting rules.
Preserve raw transcripts when possible: Keeping both raw and normalized transcripts can be useful for debugging or model evaluation. Raw transcripts reflect the literal ASR output, while normalized transcripts represent formatted text.
Test edge cases: Evaluate normalization behavior across large numbers, currency expressions, dates, multilingual speech, and so forth. Edge cases often reveal formatting inconsistencies.
Consider downstream NLP systems: Normalization can influence how downstream NLP models interpret the text. For example, converting “five hundred” to 500 may improve entity recognition or numeric analysis.
Example developer workflow
A typical developer workflow might integrate speech transcription and normalization within a broader application pipeline. Conceptually, the flow might look like this:
In this workflow, the speech-to-text API handles transcription and normalization, allowing developers to focus on application logic.
Common pitfalls
Despite its benefits, normalization can introduce challenges if applied incorrectly. One common issue is over-normalization, where transformations remove useful information from the transcript. For example, converting spoken text too aggressively may obscure how something was actually said.
Another issue involves loss of original formatting. Some applications require the literal spoken form, particularly for legal or transcription accuracy purposes.
Normalization can also conflict with domain-specific vocabulary. In financial contexts, a phrase like “twenty twenty” may refer to a fiscal year rather than a numeric quantity. Therefore normalization behavior should be evaluated within the context of their specific application.
Trends in speech text normalization
Text normalization is still an active area of development in speech systems, largely because the problem becomes harder as speech applications scale across languages, domains, and real-time use cases.
One major direction is multilingual normalization. Traditional normalization systems often rely on language-specific grammars and formatting rules. While this approach works well for individual languages, it becomes difficult to maintain as speech platforms expand to support dozens or even hundreds of languages. Modern systems are therefore moving toward more generalized normalization frameworks that can adapt to language-specific conventions—such as number grammar, currency formatting, or date ordering—without requiring extensive manual rule engineering for each language.
Another emerging direction is context-aware normalization. Spoken phrases are often ambiguous when interpreted in isolation. For example, the phrase “twenty twenty” could represent a year (2020), two numbers (20 20), or part of a time expression. Earlier normalization systems relied primarily on deterministic rules to resolve such cases. Newer approaches increasingly incorporate contextual signals from surrounding words, sentence structure, or conversation history to determine the most likely interpretation. This allows the system to make more informed decisions when formatting transcripts.
A related trend is the use of neural or sequence-to-sequence normalization models trained directly on spoken-to-written transformations. Instead of relying solely on rule-based grammars, these models learn normalization patterns from large datasets of paired spoken and written text. This approach can help systems generalize to previously unseen phrasing and linguistic variations that would be difficult to capture with handcrafted rules alone.
More recently, some pipelines have begun experimenting with LLM–based post-processing. In these architectures, the ASR system first produces a transcript, which is then refined by a language model that improves formatting, punctuation, and entity representation. Because LLMs can reason over longer context windows, they can sometimes resolve normalization decisions that depend on broader discourse context rather than local token patterns.
However, these approaches also introduce new challenges, particularly around latency, determinism, and reproducibility. Production speech systems—especially real-time transcription pipelines—must ensure that normalization remains predictable and fast enough for streaming applications. For this reason, many modern speech systems still rely on hybrid architectures that combine rule-based grammars, statistical models, and contextual signals. As speech interfaces continue to expand into areas such as voice agents, multilingual customer support systems, and meeting intelligence platforms, normalization will remain a critical layer that connects raw speech recognition output to structured, machine-readable text.
FAQs
What is text normalization in speech recognition?
Text normalization in speech recognition is the process of converting spoken-language transcripts produced by an automatic speech recognition (ASR) system into standardized written text. For example, a spoken phrase like “twenty five dollars” may be converted into “$25”. This process ensures that transcripts follow conventional written formats for numbers, dates, currencies, and other structured expressions.
What is inverse text normalization?
Inverse text normalization (ITN) converts spoken-language forms into structured written representations during speech recognition processing. For example, the spoken phrase “twenty twenty four” may be converted into “2024”. ITN is commonly used in speech-to-text pipelines to transform words representing numbers, times, dates, and units into machine-readable formats.
Why is normalization important for speech-to-text APIs?
Normalization improves the readability, consistency, and usability of transcripts generated by speech-to-text APIs. By converting spoken expressions into standardized written formats, normalized transcripts can be more easily processed by downstream systems such as search engines, analytics pipelines, databases, and natural language processing (NLP) models.
Do all speech recognition systems normalize text automatically?
Many modern speech recognition APIs include built-in text normalization as part of the transcription pipeline. However, the level of formatting and the types of expressions normalized—such as numbers, dates, currencies, and measurements—can vary depending on the speech recognition system, configuration, and application requirements.
How do numbers get converted in ASR?
Numbers in automatic speech recognition systems are typically converted through rule-based grammars, machine learning models, or hybrid approaches. These systems interpret spoken numeric expressions such as “one hundred twenty five” or “three point five” and convert them into written numeric forms like “125” or “3.5”.
Is normalization always required?
Text normalization is not always required. Some applications prefer raw transcripts that preserve the original spoken forms for accuracy, auditing, or linguistic analysis. In many production speech-to-text systems, both raw transcripts and normalized transcripts are stored so developers can choose the format that best fits their application.
Concluding thoughts
Text normalization plays a critical role in transforming speech recognition output into usable text. While ASR models focus on identifying words from audio signals, normalization ensures those words appear in formats that match how humans write and how software systems interpret data. For developers building applications on top of speech data, understanding normalization helps clarify how transcripts move through an ASR pipeline and how they interact with downstream systems.
One of the easiest ways to do that in practice is to run real audio through a speech-to-text system and inspect the resulting transcripts. Sending different types of audio—conversations, meetings, phone calls, or multilingual speech—can reveal how normalization handles numbers, dates, measurements, and punctuation across real-world scenarios.
If you're building speech-enabled applications, experimenting with a speech-to-text API such as Gladia can be a practical way to see how normalized transcripts integrate into downstream systems like search, analytics, or NLP pipelines.
Contact us
Your request has been registered
A problem occurred while submitting the form.
Read more
Speech-To-Text
Medical speech-to-text for AI scribe builders
Speech-To-Text
Migrating from self-hosted Whisper to a managed speech-to-text API
Speech-To-Text
AssemblyAI to Gladia migration guide: API mapping & setup
From audio to knowledge
Subscribe to receive latest news, product updates and curated AI content.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.