Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Migrating from Rev.ai to Gladia: what global teams should know
TL;DR: At 10,000 hours of audio per month, Rev.ai's per-hour billing compounds quickly once you add diarization, translation, and sentiment as separate line items. Language coverage gaps surface silently in production when non-English or accented audio degrades without returning an obvious error. This guide gives you the exact API payload mappings, WebSocket transition logic, and a TCO model at realistic scale to make a defensible evaluation of switching. If you decide to migrate, our all-inclusive per-hour pricing bundles every audio intelligence feature at the base rate, and most teams complete the endpoint transition and initial production validation in under 24 hours.
Switching your speech-to-text provider: A migration checklist for note-takers and contact center platforms
TL;DR: Switching your speech-to-text provider is a structural risk only if you skip the pre-migration audit. The real danger is not the cutover itself but continuing to run infrastructure that corrupts CRM entries, breaks LLM summaries, and inflates your per-hour cost with add-on fees you never modeled at scale. The four-stage phased cutover in this guide is designed to reach 100% production traffic without user-visible downtime, the same structural approach that let Aircall cut processing time by 95% and scale to over one million calls per week after adopting Gladia.
How decision intelligence improves customer service consistency in contact centers
TL;DR: Contact centers fail to deliver consistent service when routing infrastructure runs on static rules engines that cannot handle the complexity of real human conversation. Modern speech-to-text infrastructure addresses this by processing raw audio and feeding structured outputs to your CRM, using machine learning to analyze intent, sentiment, and speaker characteristics. Transcription accuracy sets the ceiling for every downstream action: a wrong word silently corrupts a CRM entry, a missed intent misfires a routing decision, and a misread sentiment score delays escalation. This playbook covers how to build and deploy that architecture without blowing your latency budget or your unit economics.
Introducing Solaria-3: The most accurate speech-to-text model for European languages
Published on Jun 10, 2026
Ani Ghazaryan
Today we're releasing Solaria-3 – the new #1 among leading speech-to-text providers on business audio and conversational speech, delivering the strongest accuracy on real English customer calls of any model tested. It is our best model to date, which we trained for the audio our customers deal with in real life: calls with background noise, people talking over each other, teams switching between a few languages in one meeting.
Here's why it exists: For years we'd watch voice models top some public leaderboard. The moment you run it on real customer recordings, the accuracy falls apart. Sub-4% WER on LibriSpeech, then 15% on a sales call with a non-native speaker and a noisy room. The benchmarks weren't wrong. They were just measuring clean, scripted audio that no enterprise has ever recorded.
So we built Solaria-3 to close that gap, and tested it against every major provider on the public benchmarks and on our own dataset of real customer calls annotated by humans. Solaria-3 ranks #1 in accuracy on the conditions that break other models. A model for multilingual Europe, built by a European player.
TL;DR
Solaria-3 is Gladia's best-in-class and most accurate speech-to-text model for European languages, built for noisy, accented, multi-speaker production audio.
It ranks #1 on business audio beating every major provider across the board.
It improves over Solaria-1 across five languages most popular amongst our users: English, French, German, Spanish, Italian.
Solaria-1 still wins on clean read-speech, formal audio, and 100+ language coverage. The two models are built to work together, not to replace each other.
Solaria-3 comes with our usual compliance coverage (SOC 2 Type II, HIPAA, GDPR, ISO 27001) and is available on both EU and US clusters with full data sovereignty.
How we measure accuracy
Most public benchmarks are measured on clean, studio-quality read speech. Take LibriSpeech, the most widely cited benchmark. It consists of audiobook recordings: a single speaker, no background noise, careful enunciation. These conditions don’t exist in production. So we evaluated Solaria-3 on two types of data:
Public benchmarks: Earnings22 (financial and business speech), Switchboard (conversational telephone audio), Common Voice (diverse accents and speakers), FLEURS (clean multilingual audio), VoxPopuli (parliamentary speech across EU languages) and Multilingual LibriSpeech (included for reference despite its limits). These allow direct comparison with other providers, and the harder ones among them are where the benchmark results come closest to reflecting real production audio: noisy, spontaneous, and conversational.
Gladia's internal production dataset: real customer recordings across five European languages. This is the closest thing to what you'll see in your pipeline, and we lean on it because public benchmarks can be gamed: it's a lot harder to overfit to audio nobody else has.
On our internal English production dataset, made up of professional meeting recordings and customer support calls, Solaria-3 achieves 9.6% WER, placing it at the top of the field and showing a 26% improvement over Solaria-1 (12.9%).
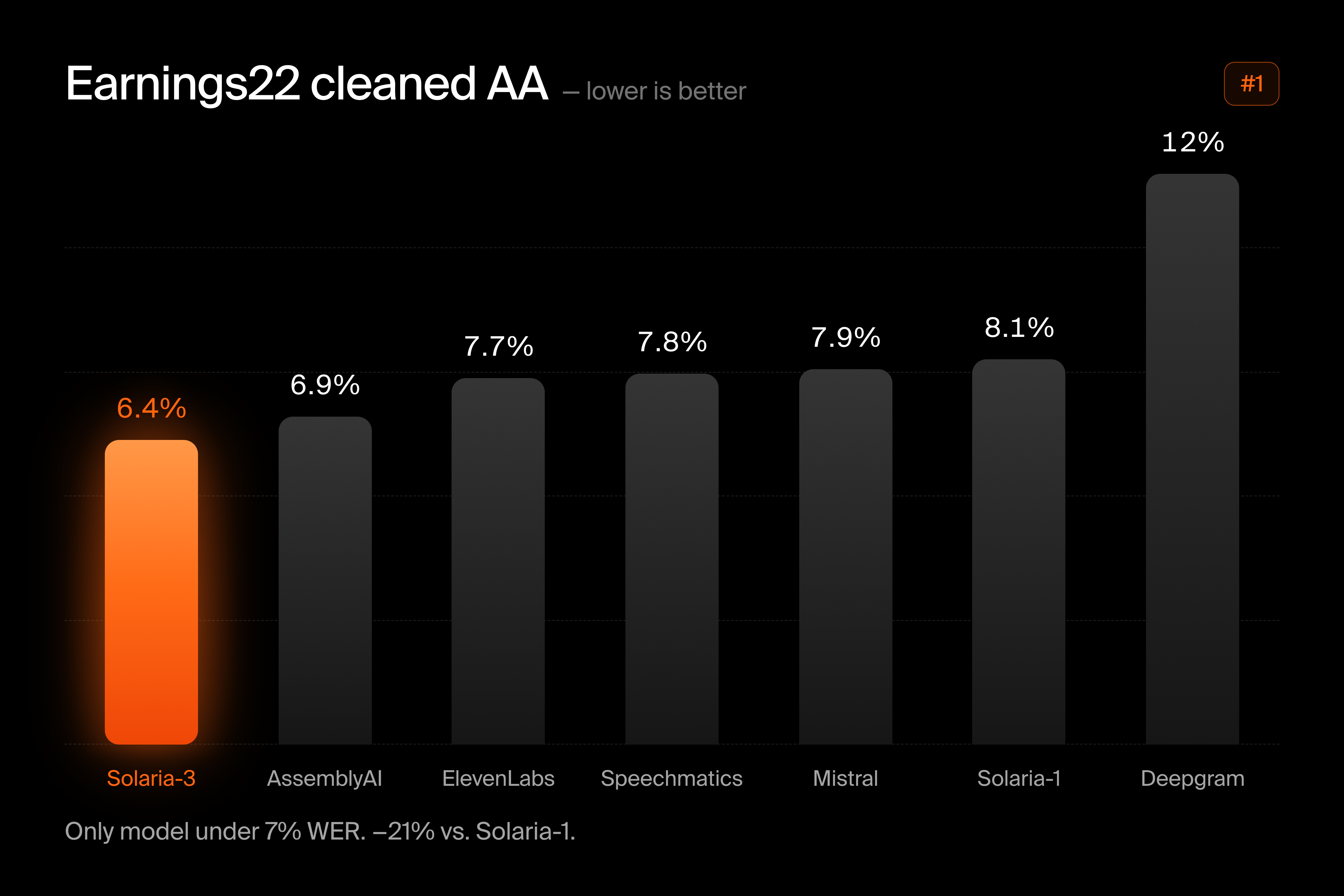
On Earnings22 Cleaned AA, the industry standard for financial and business speech, Solaria-3 ranks #1 at 6.4% WER — the only model under 7%, ahead of AssemblyAI (6.9%), ElevenLabs (7.7%), Speechmatics (7.8%), Mistral (7.9%), and Deepgram (12.0%).
The gains show up most on the audio that breaks other models: fast-paced multi-speaker calls, non-native accented English, and dense domain vocabulary.
Example 1: 15-minute earnings call (Qudian Q3 2021)
WER Comparison Across Providers
Provider
WER
Note
Solaria-3
4.2%
“Qudian’s third quarter 2021 earnings conference...”
AssemblyAI
4.7%
Similar to reference
Solaria-1
7.3%
Similar to reference
ElevenLabs
8.5%
Writes numbers as words throughout
Deepgram
10.7%
“cugen’s third quarter twenty twenty one earnings...”
Deepgram mangles the company name and writes all numbers as words, which is the kind of error that makes downstream parsing unreliable on every financial call it processes.
Example 2: 20-minute earnings briefing, non-native English speaker (TDK Q3 FY2022)
WER Comparison Across Providers
Provider
WER
Note
Solaria-3
11.2%
#1 overall
Mistral
11.6%
Similar to reference
Solaria-1
13.2%
Similar to reference
AssemblyAI
13.5%
Similar to reference
ElevenLabs
16.0%
Paraphrases instead of transcribing
Deepgram
16.8%
Writes fiscal year quarters as words
Accented English is still one of the hardest problems in speech-to-text. Solaria-3 leads here even against Mistral, which performs well on clean audio but struggles with heavy accent and compressed audio combined.
Example 3: Internal production call, fintech discussion (PayPal merchant matching)
WER Comparison Across Providers
Provider
WER
Note
Solaria-3
0.0%
Perfect transcript
AssemblyAI
7.8%
Errors on technical terms
Mistral
9.4%
Errors on technical terms
Solaria-1
10.9%
Errors on technical terms
A real customer conversation about PayPal merchant transaction: informal register, domain jargon, incomplete sentences. Solaria-3 handles it perfectly. The difference is meaningful for any sales intelligence or conversation analytics tool where technical terms are the signal.
Superior accuracy on noise and conversational speech
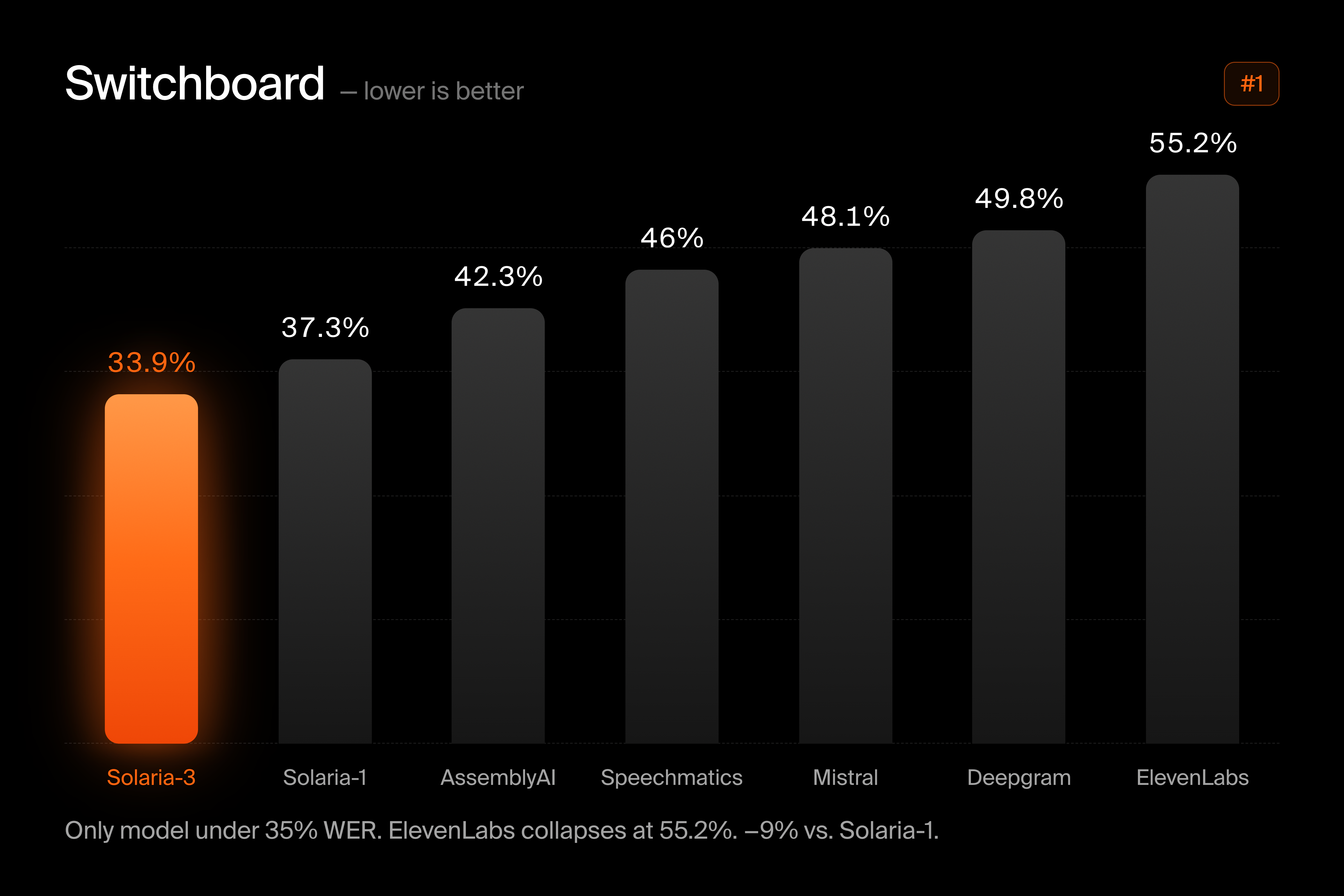
On noisy audio, Solaria-3 reaches 1.4% WER, beating most production providers, including AssemblyAI (2.1%), Deepgram (3.2%), and ElevenLabs (4.0%). On Switchboard — the hardest conversational telephone benchmark in the suite, using degraded 8kHz phone audio — Solaria-3 is #1 at 33.9% WER, the only model under 35%.
The Switchboard result is particularly significant: ElevenLabs reaches 55.2% WER on this benchmark. That is a critical failure on the kind of audio that contact centers process millions of hours of every day.
Example 1: Real-world background noise (Hugging Face database)
Reference: "The actual primary rainbow observed is said to be the effect of superimposition of a number of bows."
WER Comparison Across Providers
Provider
WER
Hypothesis
Solaria-3
0.0%
Perfect
AssemblyAI
0.0%
Perfect
Solaria-1
4.2%
“...superimposition of a number of bones”
Speechmatics
4.2%
“...superimposition of a number of bowls”
Mistral
4.2%
“...superimposition of a number of bones”
Deepgram
12.5%
“super imposition of a number of bones”
Background noise causes four providers to mishear "bows" as "bones" or "bowls." A substitution of such kind changes the meaning of the sentence entirely. This is exactly the class of error that WER on clean audio cannot predict.
Example 2: Heavy background noise, multi-sentence passage (Hugging Face database)
Reference: "We are on a four-year mission. We didn't and it cost us the game. It can be very worrying. We need to regroup. Four policemen were wounded."
WER Comparison Across Providers
Provider
WER
Hypothesis
Solaria-3
0.0%
Perfect
Solaria-1
3.4%
Similar to reference
Speechmatics
20.7%
Hallucinates “Artificial intelligence”
AssemblyAI
31.0%
“It’s not just made up by human”
Deepgram
51.7%
“we did it and it cost us the game... artificial intelligence”
ElevenLabs
103.4%
Hallucinates entire additional sentences
ElevenLabs reaches 103% WER, meaning it hallucinated more words than were actually spoken. Under noisy conditions, the failure mode is not just inaccuracy; it is confabulation. Models that hallucinate content on degraded audio are unsuitable for any use case where faithfulness to what was said is critical.
Example 3: Switchboard, degraded 8kHz telephone audio
Reference: "yeah not not even that much probably yeah"
WER Comparison Across Providers
Provider
WER
Hypothesis
Solaria-3
0.0%
“Yeah, not not even that much probably. Yeah.”
AssemblyAI
62.5%
Hallucinates “Well, that would be—”
Mistral
87.5%
Hallucinates “Well, that would be a bit”
Deepgram
87.5%
Hallucinates “well that would be yeah be a time”
Solaria-1
100.0%
Hallucinates “Well, that would be a good time.”
ElevenLabs
100.0%
Hallucinates “it would be it”
Every other model hallucinates words that were never spoken. On phone-quality audio, hallucination is the primary failure mode, and it’s the hardest to catch in production because the output looks plausible.
Note: Examples are individual utterances chosen to illustrate failure modes, not aggregate scores. Average WER across all tested audio is reported in the benchmarks section.
Most accurate model for European languages
Multilingual accuracy has been core to Gladia since day one. That’s why Solaria-1 supports 100+ languages. Yet Solaria-3 extends that commitment with a focused push on European production quality: consistent improvement over Solaria-1 across English, French, German, Spanish, and Italian, measured on our own internal production dataset.
WER Reduction by Language
Language
Real customer audio
Common Voice 24
English (EN)
−26%
−16%
French (FR)
−18%
−19%
Italian (IT)
−10%
−12%
Spanish (ES)
−9%
≈ flat
German (DE)
−3%
−13%
The gains show up on the vocabulary that matters most in production: proper nouns, domain terms, place names, and precise verbs where a single wrong word changes the meaning of a sentence.
Example 1: Challenging accent, EN (Common Voice)
Reference: "Thus the Byzantines were forced to fight alone."
WER Comparison Across Providers
Provider
WER
Hypothesis
Solaria-3
0.0%
Perfect
Speechmatics
12.5%
“focused” instead of “forced”
Solaria-1
50.0%
“Thus the bison tens were focused to fight lone”
Mistral
50.0%
“Thus the Bison Tens were focused to fight lone”
Three independent errors on an 8-word sentence: a proper noun mangled, a verb wrong, an adverb truncated. This is not an edge case. It is representative of what happens to accented speech on models not optimised for it.
Example 2: Spanish proper noun (Common Voice)
Reference: "Al acabar la temporada volvió al Alcorcón."
WER Comparison Across Providers
Provider
WER
Hypothesis
Solaria-3
0.0%
Perfect
Solaria-1
14.3%
“volvió al corcón”
Mistral
14.3%
“volvió al Corcón”
Deepgram
28.6%
“volvió al al corcón”
ElevenLabs
28.6%
“volvió al, al Corcón”
Alcorcón is a city of 170,000 people near Madrid. Every provider except Solaria-3 drops the "Al" prefix, producing a word that does not exist. For any application involving Spanish place names, including logistics, customer service, and local business, this class of error matters.
Example 3: Conversational French with stuttering (internal dataset)
Reference: "Non, observe, attends et émerveille-toi... il s'agit, il-il-il advient, pardon, il advient ce que le bébé ou le fœtus même aurait eu besoin..."
WER Comparison Across Providers
Provider
WER
Hypothesis
Solaria-3
0.0%
Faithfully captures “il, il, il advient...”
Solaria-1
15.8%
Smooths over the hesitations, drops words
Mistral
15.8%
Smooths over the hesitations, drops words
In verbatim transcription (meeting notes, medical records, legal depositions) the hesitations are not noise to be cleaned. They are part of the record. Solaria-3 captures them; most other models silently delete them.
Where Solaria-1 is still the better choice
We don't think Solaria-3 should replace Solaria-1 everywhere. Here's where Solaria-1 still wins:
Multilingual LibriSpeech: Solaria-3 scores 8.0% WER against Solaria-1's 5.9%, a 36% relative regression. It's a clean read-speech benchmark spanning a lot of languages, so if your audio is mostly clean, read-aloud material across a wide language range, Solaria-1 is the better pick.
VoxPopuli Cleaned AA: The gap holds on formal, institutional audio too. Solaria-3 scores 2.9% to Solaria-1's 2.2%, a 32% relative regression, and Solaria-1 stays ahead.
Broad multilingual coverage: Solaria-3 is tuned for five languages: EN, FR, DE, ES, and IT. Solaria-1 covers 100+, including 42 that no other API supports. If you need rare-language coverage or real multilingual breadth, Solaria-1 is still the right call.
The two models are built to work together, not to replace each other.
Try Solaria-3 for free
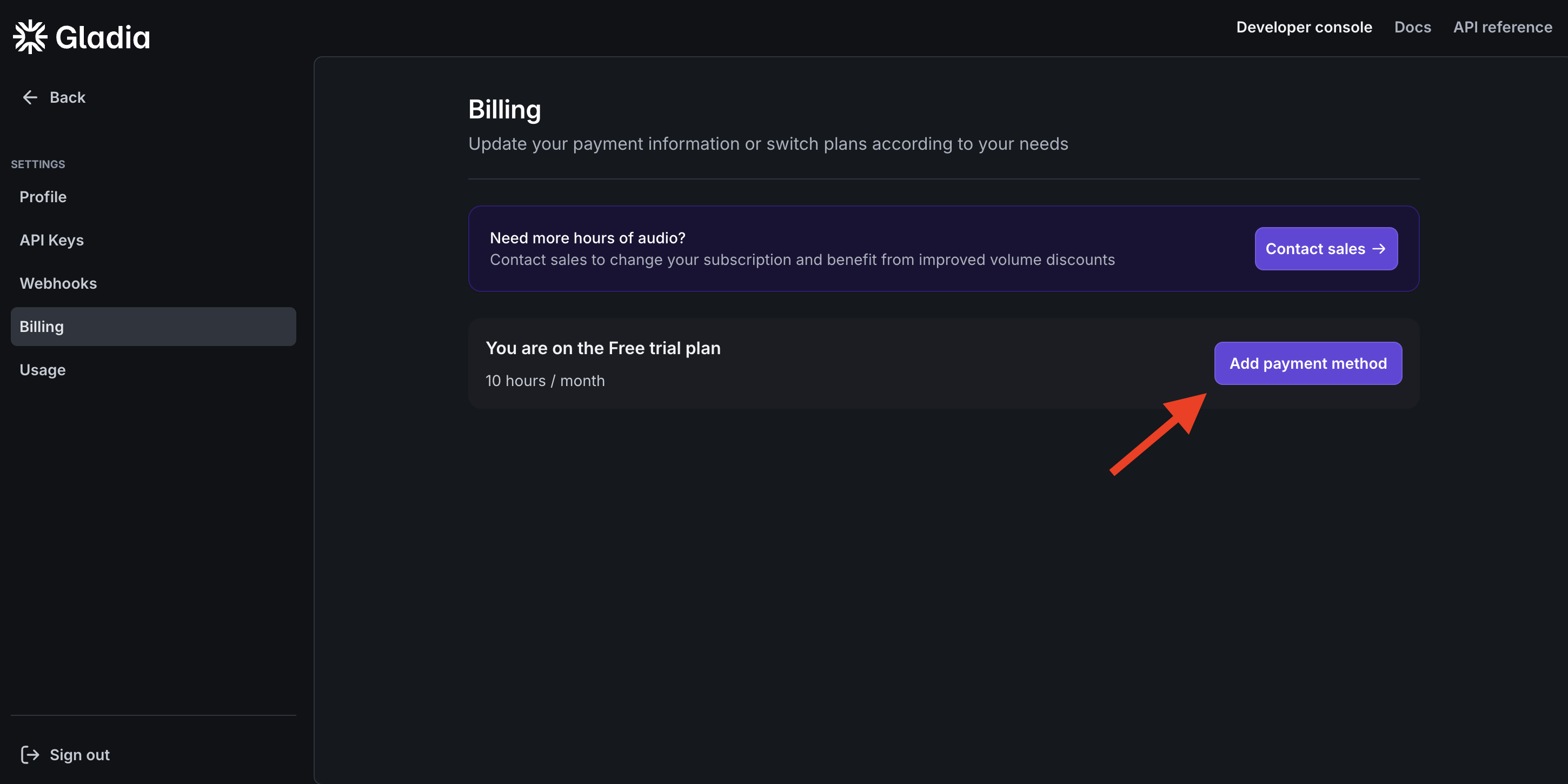
Solaria-3 is live today in Gladia's API. It’s free with code TRY-SOLARIA-3 at checkout. Go to Billing → Add payment method → Add promo code. The code is redeemable once per account for async transcription.
To switch to Solaria-3 in your API calls:
# In your transcription request, set the model parameter:
curl -X POST https://api.gladia.io/v2/transcription \ -H "x-gladia-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"audio_url": "https://your-audio-file.com/audio.mp3",
"model": "solaria-3"
}'
After the free trial, Solaria-3 is billed at standard API rates. Full documentation is available at docs.gladia.io.
If you have questions or want to share feedback on how Solaria-3 performs on your audio, reach out at support@gladia.io or join the Gladia Discord. Solaria-1 remains available and fully supported.
FAQs
Is Solaria-3 the most accurate speech-to-text model?
On the audio that matters most in production business calls, Solaria-3 ranks #1 on most benchmarks Gladia tested, leading on Earnings22 (6.4% WER), Switchboard (33.9% WER), and Gladia's internal English production dataset (9.6% WER). It is not #1 everywhere: Mistral Voxtral edges it out on noisy audio (1.0% vs. 1.4%), and Solaria-1 remains more accurate on clean read-speech and formal institutional audio.
What languages does Solaria-3 support?
Solaria-3 is optimized for five European languages: English, French, German, Spanish, and Italian. For broader coverage, Solaria-1 supports 100+ languages, including 42 not available through any other API.
Should I use Solaria-3 or Solaria-1?
Use Solaria-3 for European real-world audio — business calls, contact centers, and noisy or accented recordings. Use Solaria-1 for clean read-speech, formal institutional audio, or languages outside the core five. The two models are designed to complement each other, not replace.
How does Solaria-3 compare to Deepgram, AssemblyAI, and ElevenLabs?
On Earnings22, Solaria-3 (6.4% WER) beats AssemblyAI (6.9%), ElevenLabs (7.7%), and Deepgram (12.0%). On Switchboard, it reaches 33.9% WER while ElevenLabs reaches 55.2%. On noisy audio it outperforms all three, though Mistral Voxtral leads overall.
Where does Solaria-3 underperform Solaria-1?
On Multilingual LibriSpeech (8.0% vs. 5.9%, a 36% relative regression) and VoxPopuli (2.9% vs. 2.2%, a 32% relative regression) — both clean, formal read-speech benchmarks. These regressions are published openly. For that kind of audio, Solaria-1 is the better choice.
How was Solaria-3 benchmarked?
On public benchmarks (Earnings22, Switchboard, Common Voice, FLEURS, VoxPopuli, and Multilingual LibriSpeech) for direct comparison with other providers, and on Gladia's internal dataset of real customer recordings across five European languages — human-annotated and far harder to overfit to than public data.
How much does Solaria-3 cost and how do I try it?
Solaria-3 is free for 5 days with the code TRY-SOLARIA-3 (Billing → Add payment method → Add promo code). After the trial, it's billed at standard API rates. To use it, set "model": "solaria-3" in your transcription request.
Contact us
Your request has been registered
A problem occurred while submitting the form.
Read more
Speech-To-Text
Migrating from Rev.ai to Gladia: what global teams should know
Speech-To-Text
Switching your speech-to-text provider: a migration checklist for note-takers and CCaaS
Speech-To-Text
How decision intelligence improves customer service consistency in contact centers
From audio to knowledge
Subscribe to receive latest news, product updates and curated AI content.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.