Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Call center transcription software: what enterprises should look for in 2026
TL;DR: Most contact centers evaluate transcription software using clean-audio lab benchmarks, then watch QA automation break down when BPO (Business Process Outsourcing) agents switch languages mid-call or phone-line noise degrades the signal. In 2026, the criteria that matter are real-world multilingual WER, all-inclusive per-hour pricing, and data sovereignty that holds up under GDPR and HIPAA audit. For enterprise teams, the highest-ROI evaluation step is testing on real BPO call samples rather than vendor demo audio, and asking every shortlisted provider for an all-in per-hour price with diarization, sentiment, and entity extraction enabled.
PII redaction for call recordings: how ingestion-level redaction keeps calls PCI compliant
TL;DR: Legacy pause-and-resume systems don't remove agents, local desktops, or telephony infrastructure from PCI DSS audit scope. Automated, ingestion-level PII redaction scrubs sensitive data before it reaches any database. By removing cardholder data at the ingestion layer, contact center platforms using automated redaction can potentially reduce audit complexity, cut agent handle time (AHT), and protect downstream CRM and LLM pipelines from corrupt data. The accuracy floor for reliable entity detection in PCI audits is significantly higher than for standard QA transcription, making STT model selection a compliance decision as much as a product one.
GDPR, SOC 2, and ISO 27001 speech-to-text: the contact center compliance and certification guide
TL;DR: When your contact center routes voice data through a transcription vendor, every certification gap in that vendor's stack becomes your compliance liability. Voice recordings qualify as personal data under GDPR Article 4, and processing them through uncertified APIs creates direct financial exposure. This guide breaks down what GDPR, SOC 2 Type II, ISO 27001, HIPAA, and PCI DSS each require of your audio infrastructure vendor and maps those requirements to the QA coverage rates and cost-per-contact metrics you manage daily. We hold GDPR, SOC 2 Type II, ISO 27001, HIPAA, and PCI DSS certifications, and never use customer audio for model training on Growth or Enterprise plan.
Meeting assistants have spent a decade getting better at recording and almost no time getting better at acting. That is finally changing. A new generation of tools is crossing the line from capture to action: they look things up mid-call, intervene when something required is missing, draft the follow-ups, reason across your meeting history, expose meeting context to other AI tools, and synthesize hours of conversation into formats you can actually consume.
An agentic feature takes action on the user's behalf. It doesn't just record information for someone to act on later but changes what happens in or after the meeting. Below are the six agentic features showing up in real products today, the companies leading each one, and what they mean for anyone building or buying in this space.
TL;DR:
Live in-call lookups: the assistant retrieves information in real time during a call and surfaces it in the conversation. Example: Fireflies' Ask Fred.
Real-time intervention: the assistant speaks up when something required is missing, changing the outcome of the meeting, not just the record. Example: Abridge in clinical encounters.
Autonomous follow-up and deal actioning: the assistant drafts personalized follow-ups, updates the CRM, and flags stalled deals after the meeting. Example: Gong AI agents.
Stateful reasoning across meeting history: the assistant doesn't just retrieve text from past calls; it reasons across them to answer questions that span weeks of context. Example: Sana Agents.
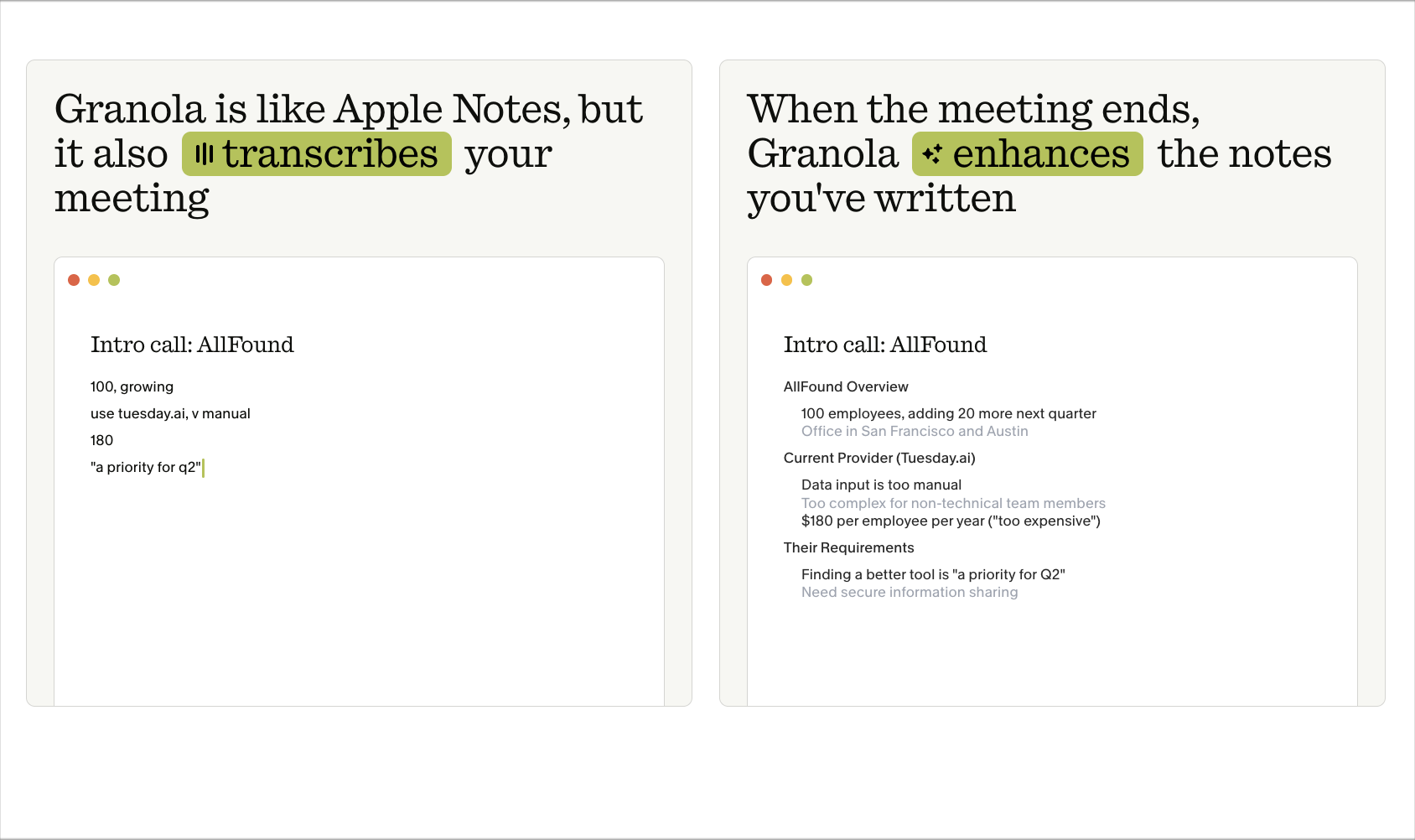
Meeting context as a service to other agents: the assistant exposes your meeting notes as a knowledge layer that other AI tools can query through open protocols. Example: Granola via MCP.
Source-grounded synthesis: the assistant transforms meeting content into new formats to make hours of context consumable in minutes. Example: NotebookLM's Audio Overviews.
Why is this shift happening now?
For most of the last decade, the hard part of meeting AI was the transcript. Speech-to-text accuracy was the bottleneck, latency was unworkable for anything real-time, and reasoning over a noisy multi-speaker conversation was beyond what models could do reliably. So the product surface settled where it could: a clean recap, a searchable archive, maybe an action-items list. The user did the rest.
Three things shifted in the last 18 months. Real-time multilingual transcription got cheap and accurate enough to run on every call, not just the ones worth paying for. LLMs got good enough to reason over a live transcript and produce something useful before the meeting ends. And users stopped seeing "AI in the meeting" as novel and started asking it to do the work, including drafting, updating, deciding.
Together, those changes moved the ceiling. A meeting assistant can now hear the conversation in real time, understand what's in it, and act on what it understands. That's the foundation every agentic feature is built on.
1. Live in-call lookups
Think about the work a junior teammate used to do in a side channel during a sales call: pulling up funding history, checking when this account last raised a pricing concern, finding a LinkedIn profile mid-conversation. That work is now an agentic feature. A live in-call lookup is a meeting assistant retrieving information in real time during a call and surfacing it inside the conversation, not in the post-meeting recap.
Fireflies leads here. Its in-meeting assistant, Fred, behaves like a teammate sitting in the call: through Ask Fred, participants can query Fireflies while the call is still happening and get answers in the moment. Voice-driven interaction takes it a step further — saying "Hey Fireflies" pulls up clarifications without anyone touching a keyboard.
The reason this matters is timing. A pricing detail surfaced ten minutes after the call ended is a follow-up email. The same detail surfaced ten seconds into a pricing objection is a closed deal. And the ceiling on how well any of this works is the underlying transcription (see our take on meeting transcription best practices).
2. Real-time intervention
The next step is the assistant not waiting to be asked. Real-time intervention is an agentic pattern where the meeting assistant speaks up (unprompted) when something required is missing from the conversation. The shift is meaningful as it changes the outcome of the meeting.
Healthcare is the clearest place to see it. Abridge listens while a doctor speaks with a patient and structures a clinical note in real time, capturing history, exam, assessment, and plan as the conversation unfolds. Its real-time orders feature pushes further. When the clinician mentions a lab, an imaging study, or a referral, the order surfaces directly in the EHR for review. The same logic applies to documentation gaps: if a billable detail like allergy history hasn't come up, the assistant can flag it before the visit ends, when it's still cheap to ask. No post-visit scramble.
But the pattern generalizes well beyond medicine. Sales discovery calls with a methodology to follow. Compliance interviews. Qualification frameworks. Intake processes. Wherever a checklist is supposed to be covered in a conversation, real-time intervention closes the gap between what should have been asked and what actually was. The dependency is the same across all of them: the system has to understand the conversation as it happens, which is why real-time multilingual transcription is the foundation.
3. Autonomous follow-up and deal actioning
After the meeting ends, the work begins — or used to. Autonomous follow-up is an agentic pattern where the assistant takes post-meeting action automatically: drafting personalized follow-up emails, updating CRM fields, and flagging stalled deals for re-engagement. The rep stops doing the work and starts reviewing it.
Let's take Gong as an example. Gong AI agents draft follow-up emails based on what was actually discussed, generate account briefs with full deal and contact context, and flag deals where key objections went unaddressed. The AI Deal Reviewer agent goes one further, suggesting deal updates and writing them back to the CRM automatically.
Time savings compound across a team. A rep running five discovery calls a day no longer loses an hour each night reconstructing them from memory in Salesforce; the work arrives in draft form, and editing is faster than authoring. We've seen this dynamic up close in our Claap case study, where post-call automation directly affected retention and conversion.
4. Stateful reasoning across meeting history
The first three patterns mostly operate on a single meeting — what's being said now, what was said in this call, what to send after this conversation. The next step is reasoning across many meetings at once. Stateful reasoning is the pattern where the assistant treats your full meeting history as a structured knowledge base and answers questions that span weeks of context, not just one call.
Sana is pushing on this. Sana Agents go beyond retrieval — they reason across SOPs, internal documents, and meeting history to handle questions like "which deals in the pipeline mentioned the new compliance requirement, and what did we commit to?" or "summarize every customer objection raised about pricing in Q3 and group them by segment." That's not a search query, it's a multi-step reasoning task that depends on stateful context across hundreds of conversations.
The underlying mechanism is retrieval-augmented generation done well — pulling the right meeting snippets, the right policy docs, the right CRM records, and reasoning over them together. Get retrieval wrong and the agent confidently hallucinates; get it right and you have something close to an analyst that has read every meeting transcript your company has ever produced.
5. Meeting context as a service to other agents
The patterns above all live inside the meeting assistant itself. The next shift is treating the meeting assistant as a knowledge layer that other tools can plug into. Instead of asking the assistant to draft your email, you let Claude or ChatGPT or your IDE reach into your meeting notes directly and use that context wherever you're already working.
Granola is an early mover here. Through Model Context Protocol (MCP) support, Granola exposes your meeting notes as a queryable context source for other AI tools. A developer in Cursor can ask their coding assistant to reference yesterday's product spec meeting without copy-pasting anything. A salesperson drafting an email in Claude can pull in last week's discovery call notes by reference. The meeting assistant stops being a destination and starts being infrastructure.
This is a quieter agentic pattern than the others — there's no flashy in-meeting moment — but it may be the most consequential. Once meeting context becomes addressable by any AI tool through an open protocol, the value of the meeting assistant shifts from owning the UI to owning the data layer underneath.
6. Source-grounded synthesis
The last pattern flips the direction. Instead of the assistant acting on your meetings, it transforms them into new formats you can act on more easily. Source-grounded synthesis is the pattern where the assistant takes raw meeting content — transcripts, notes, attached documents — and produces something genuinely new: a briefing, a debate, a podcast.
NotebookLM made the canonical version of this visible with Audio Overviews — two synthetic hosts having a conversational, surprisingly natural-sounding discussion of whatever source material you load in. Drop in three hours of customer calls and a competitive analysis doc, and twenty minutes later you have a ten-minute audio briefing you can listen to on a walk. The synthesis isn't just compression; it's reframing, with the AI choosing what to emphasize, what to question, and what to skip.
For meeting workflows, this matters when context is too dense to read. New hires onboarding to an account with two years of call history. Executives prepping for a board meeting across twelve product reviews. The assistant becomes a way to make hours of meeting context consumable in minutes, in formats that fit how people actually work — which often isn't reading another document.
The future of agentic features
The throughline across all six patterns is the same: the meeting assistant stops being a passive recorder and starts taking action on the user's behalf — sometimes during the meeting, sometimes after, sometimes both, and increasingly outside the meeting assistant entirely. Lookup, intervention, follow-up, stateful reasoning, context-as-a-service, and source-grounded synthesis. Six agentic surfaces, a growing set of companies pushing them, and a category that looks very different from the AI notetakers of two years ago.
If you're building in this space, the underlying capability stack matters as much as the surface feature. Real-time lookup needs fast, accurate transcription. Real-time intervention needs structured understanding of the conversation as it happens. Autonomous follow-up needs reliable extraction of commitments, objections, and next steps. Stateful reasoning needs solid retrieval over clean, well-indexed transcripts. Context-as-a-service needs the assistant's data to be addressable through open standards. Source-grounded synthesis needs source material faithful enough to the original conversation that the new format doesn't introduce errors. Each agentic feature is only as good as the speech-to-text model underneath it.
Want to go deeper? We reviewed 100+ vendors and surveyed 2,000+ users to map the meeting assistant landscape in detail: which vendors lead on which capabilities, where the moats are forming, and how the stack is likely to consolidate. Read the full report.
FAQ
What is an agentic meeting assistant?
An agentic meeting assistant is an AI tool that takes action on the user's behalf during or after a meeting, rather than only recording it. Unlike traditional notetakers that produce a transcript and summary, agentic assistants look up information mid-call, intervene when required data is missing, draft follow-up emails, update CRM fields, reason across your full meeting history, expose meeting context to other AI tools, and synthesize hours of conversation into new formats.
How is an agentic meeting assistant different from an AI notetaker?
An AI notetaker captures information — transcripts, summaries, action items — and hands it back to the user to act on. An agentic meeting assistant takes the action itself: drafting the follow-up, updating the system of record, flagging a stalled deal, or surfacing a missing question in real time. The difference is between recording and doing.
Which companies are leading on agentic meeting features?
Fireflies leads on live in-call lookups with its Ask Fred interface. Abridge leads on real-time intervention in clinical encounters, structuring notes and drafting orders during the visit. Gong leads on autonomous follow-up and deal actioning, with AI agents that draft emails, update the CRM, and flag deal risk. Sana is pushing on stateful reasoning across meeting history with Sana Agents. Granola is opening up meeting context to other AI tools through MCP. NotebookLM is leading on source-grounded synthesis with its Audio Overviews.
What is a live in-call lookup?
A live in-call lookup is an agentic feature where a meeting assistant retrieves information in real time during a call — pricing history, prior objections, account context, or external data — and surfaces it inside the conversation instead of after. Fireflies' Ask Fred is the canonical example.
What is MCP and why does it matter for meeting assistants?
Model Context Protocol (MCP) is an open standard that lets AI tools query external context sources in a structured way. For meeting assistants, MCP means your meeting notes can be made addressable by other AI tools — Claude, ChatGPT, coding assistants, internal agents — without bespoke integrations for each one. Granola is one of the early meeting tools to expose its data this way.
Why does speech-to-text quality matter for agentic meeting assistants?
Every agentic feature in a meeting assistant runs on top of a transcription layer. Live lookups depend on low-latency, accurate transcription to know what was just said. Real-time intervention depends on structured understanding of the conversation as it unfolds. Autonomous follow-up depends on reliable extraction of commitments and objections from the call. Stateful reasoning and source-grounded synthesis both depend on clean transcripts as the substrate they reason and synthesize from. Transcription quality is the performance ceiling for everything built on top of it.
Contact us
Your request has been registered
A problem occurred while submitting the form.
Read more
Speech-To-Text
Call center transcription software: what enterprises should look for in 2026
Speech-To-Text
PII redaction for call recordings: how ingestion-level redaction keeps calls PCI compliant
Speech-To-Text
GDPR, SOC 2, and ISO 27001 speech-to-text: the contact center compliance and certification guide
From audio to knowledge
Subscribe to receive latest news, product updates and curated AI content.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.