Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Call center voice analytics: use cases, benefits, and how it works
TL;DR: Contact centers that rely on manual QA for call review typically sample only a small fraction of their total call volume, leaving the vast majority of audio unanalyzed. Voice analytics fixes this by converting raw phone calls into structured, LLM-ready data that feeds QA scorecards, CRM entries, and coaching workflows automatically. The catch is that telephony audio is uniquely hostile to standard speech APIs because narrowband codecs and packet loss break models trained on clean audio. This article explains the technical pipeline, the metrics that matter, and the infrastructure requirements that separate production-ready systems from vendor demos.
Customer sentiment analysis: methods, tools, and what voice data adds
TL;DR: Reliable sentiment analysis requires WER below 5%, speaker diarization that separates customer and agent emotion, and language models that hold performance across accents and code-switching. Text-only sentiment tools miss critical voice signals (pace, talk-over, vocal intensity) that predict churn before survey data surfaces the same risk. Automated sentiment scoring on high-accuracy transcripts shifts QA from sampling 2–5% of calls to monitoring 100% of them, the only coverage level at which churn risk and agent burnout surface early enough to act on.
Named Entity Recognition from call transcripts: improving precision
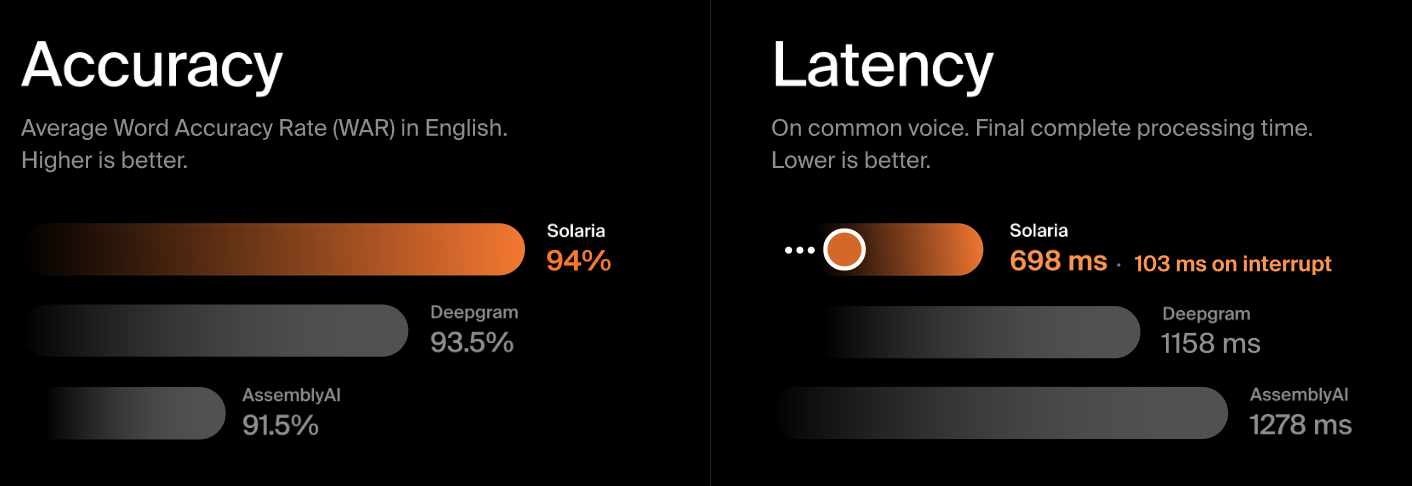
TL;DR: Standard NER models trained on clean text lose up to 27 F1 points when applied to raw ASR output. For CCaaS operations running automated QA and CRM sync, that gap translates directly into missed account numbers, corrupted customer records, and unreliable coaching scores. The fix starts at the transcription layer. Our Solaria-1 model delivers lower WER on conversational speech and 3x lower DER than alternatives, giving your NER pipeline a clean text foundation before a single field is written to the CRM.
7 AssemblyAI alternatives: Specialized speech AI solutions for your specific needs
Published on Jan 30, 2026
By Matija Laznik
AssemblyAI has become a widely-used speech AI platform, offering developers a comprehensive suite of tools for transcribing audio and extracting valuable insights. Its combination of accurate transcription, Audio Intelligence features like sentiment analysis and summarization, and the innovative LeMUR framework for applying large language models to voice data has made it a popular choice for companies building voice-enabled applications.
But as your audio processing requirements become more specific, you might find yourself needing capabilities that extend beyond what a generalist platform can provide. Perhaps you need to transcribe conversations where speakers switch between languages mid-sentence. Maybe compliance requirements demand that audio never leaves your infrastructure. Or you might need human-verified accuracy for legal depositions where AI errors carry real consequences.
That's where this guide comes in. It explores dedicated AssemblyAI alternatives that excel where you need them most, whether you're looking to:
Process real-time multilingual conversations with seamless code-switching across 100+ languages
Train custom speech models on your proprietary data and deploy on-premises
Get a unified speech-to-text and text-to-speech platform with flexible deployment options
Achieve human-verified 99% accuracy without writing any code
Self-host an open-source solution for complete data control at zero API cost
Process audio entirely on-device without any cloud transmission
Stream transcriptions token-by-token at very low latency with competitive pricing
This isn't about finding a "better" platform than AssemblyAI. It's about finding the right fit for your specific requirements. Some readers might use these tools alongside AssemblyAI for specialized use cases, while others might replace it entirely. Let's dive into the alternatives.
Best alternative for real-time multilingual transcription & data privacy
Gladia stands out for its ability to handle conversations where speakers switch between languages, supporting 100+ languages with seamless code-switching, alongside strong data privacy controls for enterprise teams. Its proprietary Solaria-1 model reduces hallucinations while maintaining sub-300ms real-time latency.
Best alternative for custom model training and deployment flexibility
Deepgram is a strong fit for organizations needing to train custom speech models on proprietary data and deploy on-premises or in dedicated cloud environments. Its Voice Agent API provides unified STT, TTS, and LLM orchestration.
Best alternative for unified STT and TTS with flexible deployment
Speechmatics offers both speech-to-text and text-to-speech in a single platform, with on-premises, cloud, and hybrid deployment options that provide flexibility for various compliance requirements.
Best alternative for human-verified accuracy without developer expertise
Rev offers 99% human-verified transcription accuracy through a no-code web interface, making it ideal for legal, medical, and academic professionals who need precision without technical overhead.
Best alternative for self-hosted free transcription
OpenAI Whisper is a completely free, MIT-licensed open-source solution that runs entirely on your own infrastructure, eliminating recurring API costs while providing complete data sovereignty.
Picovoice processes audio 100% on-device without any cloud transmission, providing intrinsic privacy through architecture rather than policy, with zero network latency for edge and embedded applications.
Best alternative for token-level streaming at competitive pricing
Soniox delivers very fast real-time transcription (targeting sub-200ms latency) at a low price point (~$0.10/hr), with built-in translation and transcription bundled into a single rate.
What is AssemblyAI?
AssemblyAI is a speech AI platform that provides developers with advanced AI models for transcribing and understanding human speech through a REST API. Founded in 2017 by Dylan Fox, the platform has grown to serve startups and Fortune 500 companies alike, processing millions of API calls daily.
Its key features include:
Speech-to-text: Accurate transcription for both pre-recorded audio files and real-time streaming, supporting 99+ languages for pre-recorded content
Speaker diarization: Identifies and distinguishes between different speakers in a conversation
Sentiment analysis: Detects the emotional tone of each sentence as positive, negative, or neutral
Topic detection: Automatically identifies subjects discussed using the IAB Content Taxonomy
Summarization: Generates concise summaries in various formats including bullet points and headlines
Content moderation: Flags sensitive or inappropriate content for platform safety
PII redaction: Automatically removes personally identifiable information from transcripts
LeMUR Framework: Applies large language models to transcribed speech for Q&A, custom summaries, and action item extraction
AssemblyAI's strength lies in its comprehensive approach to audio intelligence.
When you submit audio through their API, you get not just a transcript but a rich set of insights: who said what, how they felt when saying it, what topics they discussed, and automated summaries that capture key points. The LeMUR framework takes this further by enabling developers to ask custom questions of transcripts or extract specific information using the power of LLMs.
The platform is designed with developers in mind, offering well-documented APIs and SDKs for Python and JavaScript (note: the Java SDK was archived in 2025 and is no longer maintained), and a generous free tier with $50 in credits. For enterprise customers, AssemblyAI provides SOC 2 Type 2 compliance, HIPAA support, and options for self-hosted deployments.
However, organizations with specific requirements may find that specialized alternatives better serve their needs.
Whether that's handling complex multilingual conversations, deploying entirely on-premises, achieving human-level accuracy, or processing audio on-device without any cloud transmission, the alternatives explored below each excel in their particular domain.
How this list of AssemblyAI alternatives was curated
After testing AssemblyAI and researching the speech-to-text market, this evaluation identified specific scenarios where users often need more specialized capabilities than AssemblyAI's comprehensive approach provides. While AssemblyAI is excellent for many transcription and audio intelligence use cases, the focus here is on platforms that excel at particular jobs:
Processing multilingual conversations where speakers switch between languages naturally
Training custom speech models on industry-specific terminology and deploying within your own infrastructure
Getting both speech-to-text and text-to-speech from a single platform with flexible deployment
Achieving human-verified accuracy for mission-critical transcription without technical expertise
Self-hosting transcription for complete data sovereignty and zero recurring API costs
Processing audio entirely on-device for scenarios where data cannot leave the local environment
Streaming transcriptions at the lowest latency and cost for high-volume real-time applications
Each platform on this list excels in one of these specific areas. You might use them alongside AssemblyAI for specialized use cases, or choose one as a full replacement depending on your primary requirements.
❗ This guide isn't covering every single speech-to-text tool on the market\! The focus is on highlighting the best alternatives that address specific limitations or use cases where AssemblyAI may not be the optimal choice. The goal is to help you find tools that cater to your specific needs.
Gladia — best alternative for real-time multilingual transcription & data privacy
Gladia is an AI-powered audio intelligence platform built specifically for developers and enterprises who need to process multilingual audio at scale.
Founded in 2022 in Paris, the company was born from CEO Jean-Louis Queguiner's frustration with existing transcription services that couldn't accurately understand his French accent or handle conversations where speakers naturally switch between languages.
Its key features include:
100+ Language Support with Code-Switching: Transcribes conversations where speakers alternate between languages mid-sentence without requiring manual language selection
Solaria-1 Model: Gladia's proprietary speech recognition model supporting both real-time and async transcription, engineered to reduce hallucinations and improve enterprise reliability with real-life, noisy audio
Sub-300ms Real-Time Latency: Delivers transcriptions in under 300 milliseconds for live streaming applications
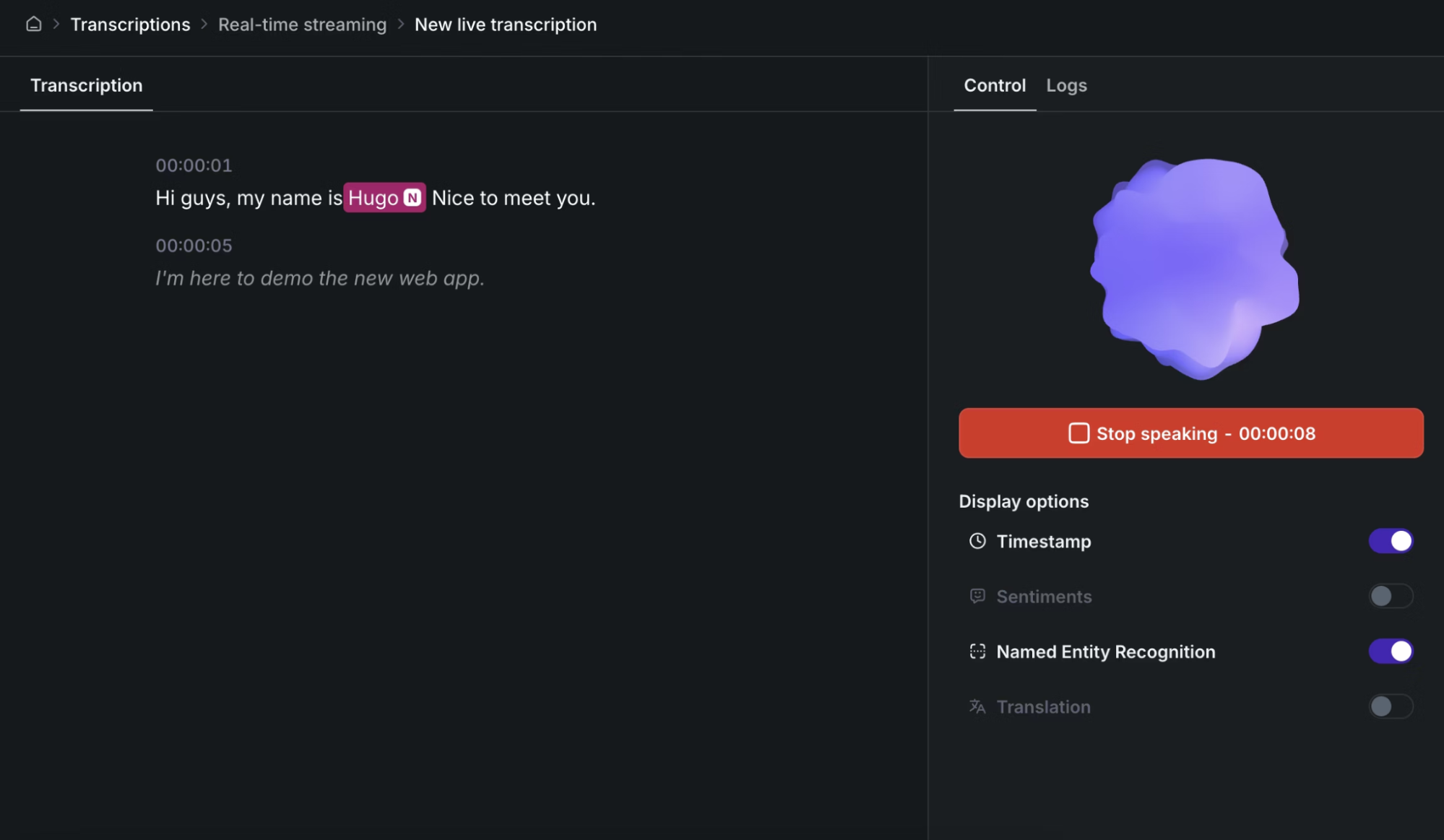
Comprehensive Audio Intelligence: Includes speaker diarization, sentiment analysis, summarization, named entity recognition, and translation through a single API
Data Privacy for Paid Plans: Does not use audio from Pro and Enterprise customers to retrain models, with zero-day data retention options available
For organizations processing international customer calls, multilingual meetings, or content from diverse global sources, Gladia provides capabilities that may offer advantages over AssemblyAI's multilingual handling, particularly around code-switching and accent diversity.
Why choose Gladia over AssemblyAI for multilingual transcription
While AssemblyAI offers solid transcription across many languages, Gladia distinguishes itself in several key areas for teams processing multilingual audio.
One of Gladia's most significant advantages is its native support for code-switching, the natural phenomenon where speakers alternate between languages within the same conversation or even mid-sentence.
This is common in international business settings, multilingual households, customer support for global companies, and media content featuring diverse speakers.
When a speaker in a sales call naturally shifts from English to Spanish to explain a concept, or when a support agent switches to a customer's native language for clarity, Gladia's models detect and transcribe these transitions automatically.
However, Gladia's specialized focus on multilingual handling, combined with their Solaria-1 model optimizations, may provide advantages for teams where multilingual conversations are the primary use case.
⚡ Gladia in action: Consider a European contact center handling customer inquiries across multiple countries. A customer might start a conversation in French, switch to English when discussing technical specifications, and include German product names. Gladia's real-time transcription captures each language transition accurately, enabling the AI agent assist system to provide relevant prompts regardless of which language the conversation is currently in.
Reduced hallucinations with Solaria-1: enterprise-grade reliability
Gladia's proprietary Solaria-1 model addresses one of the most significant concerns with ASR systems: hallucinations, where the model generates text that wasn't actually spoken.
This can manifest as invented words, repeated phrases, or entirely fabricated sentences, particularly problematic for enterprise applications where transcript accuracy has business or compliance implications.
Solaria-1 is trained on diverse audio, including noisy environments and phone-quality recordings, specifically to reduce these failure modes with real-life, noisy audio. The model supports both real-time and asynchronous transcription modes, a dual-mode capability that is a key technical differentiator.
AssemblyAI's Universal model also claims industry-leading accuracy and has its own hallucination mitigation approaches, including a reported 30% reduction in hallucination rates compared to Whisper Large-v3.
However, Gladia's specific focus on accuracy and their transparent reporting on hallucination reduction makes them a strong choice for teams who have experienced reliability issues with other solutions.
⚡ Gladia in action: A compliance team at a financial services firm needs to transcribe recorded client calls for regulatory archival. Standard ASR implementations occasionally generated phantom financial figures or repeated phrases that didn't exist in the original audio. After switching to Gladia's Solaria-1, the team saw significantly fewer instances requiring manual correction, reducing their review workload and improving confidence in their compliance records.
Data privacy commitment: control over your audio data
Gladia takes an explicit stance on data privacy that differentiates it from many competitors. For Pro and Enterprise customers, Gladia does not use audio to retrain their models by default. Free-tier audio may be used for training purposes.
For enterprise customers, Gladia offers additional controls including zero-day data retention (audio is processed and immediately deleted), customizable retention policies (1 day, 1 week, or 1 month), and the ability to request complete removal of usage data. The platform is GDPR compliant, HIPAA compliant, and has achieved SOC 2 Type 2 certification.
AssemblyAI also offers strong security certifications and data controls. However, Gladia's explicit positioning around data privacy, including their public statements about not using customer data for model training without consent, may resonate with organizations where this is a primary concern.
⚡ Gladia in action: A healthcare technology company building a patient intake system needs to transcribe sensitive medical conversations. Regulatory requirements and internal policy prohibit using any service that might incorporate patient audio into shared machine learning models. Gladia's explicit commitment to not training on customer data (for paid plans), combined with zero-day retention options, allows the company to proceed with confidence in their compliance posture.
Real-time performance for voice applications
For applications requiring immediate transcription, such as AI voice agents, live captioning, or real-time agent assist systems, latency is critical. Gladia delivers transcriptions with latency under 300 milliseconds, enabling natural conversational experiences where the AI can respond appropriately without awkward pauses.
The platform uses WebSocket connections for streaming audio and provides both partial and final transcripts, allowing applications to display in-progress text while waiting for higher-confidence final results. Voice Activity Detection helps identify speech versus silence for more accurate transcript boundaries.
AssemblyAI also offers real-time streaming with approximately 300ms median latency. Both platforms are competitive in this space, though Gladia's optimization specifically for real-time multilingual scenarios may provide advantages for applications serving international audiences.
🏅 NOTE:Other multilingual-focused providers were also evaluated for this category. Gladia's specialized focus on code-switching, combined with the Solaria-1 model optimizations and explicit data privacy positioning, makes it a strong choice for teams where multilingual conversation handling is a primary requirement.
Gladia pricing
Gladia offers usage-based pricing with separate rates for real-time and asynchronous transcription. This distinction matters because real-time transcription (for voice agents, live captioning) and async transcription (for recorded calls, meeting notes) serve different use cases with different technical requirements. All features like speaker diarization, sentiment analysis, and translation are bundled into the base price with no hidden add-ons.
You process multilingual conversations with code-switching: If your audio regularly contains speakers switching between languages mid-conversation, whether in international customer support, global sales calls, or multilingual media content, Gladia's specialized code-switching capabilities are specifically optimized to handle these scenarios.
You need enterprise-grade accuracy with reduced hallucinations: If you've experienced reliability issues with ASR implementations generating phantom text, Gladia's Solaria-1 model is specifically engineered to address these failure modes for enterprise use cases, particularly with real-life, noisy audio.
Data privacy is a primary concern: If your organization requires guarantees that audio won't be used for model training (available on Pro and Enterprise plans), or needs zero-day data retention for compliance reasons, Gladia's transparent privacy positioning and configurable retention policies provide the controls you need.
Deepgram — best alternative for custom model training and deployment flexibility
Deepgram is a foundational AI company specializing in voice technology that provides an enterprise-grade speech-to-text platform built on end-to-end deep learning.
Founded in 2015 by three former physicists who applied dark matter detection techniques to speech recognition, the company offers capabilities that address specific enterprise requirements: the ability to train custom models on proprietary data and deploy outside of cloud infrastructure.
Its key features include:
Custom model training: Train speech models on your own datasets for dramatically higher accuracy with industry-specific terminology, product names, and specialized vocabularies
Flexible deployment: Cloud API, on-premises self-hosted (Docker/Kubernetes), or dedicated single-tenant environments in your preferred cloud region
Voice agent API: Unified STT, TTS, and LLM orchestration in a single streaming pipeline for conversational AI applications
Ultra-low latency: Sub-300ms for real-time streaming, with batch processing capable of transcribing one hour of audio in approximately 30 seconds
Enterprise SLAs:99.9% uptime guarantees with dedicated infrastructure options for high-volume deployments
For organizations in regulated industries, those with unique vocabulary requirements, or teams building real-time voice agents, Deepgram provides architectural flexibility that some cloud-focused services may not offer.
Why choose Deepgram over AssemblyAI for custom models and deployment
1. Custom model training for domain-specific accuracy: AssemblyAI offers "Word Boost" to improve recognition of specific terms, but this is fundamentally different from training entirely custom speech models.
Deepgram allows organizations to train on proprietary datasets, achieving accuracy levels for specialized terminology that generic models cannot match. Medical practices with complex pharmaceutical names, law firms with case-specific proper nouns, and financial services with unique product names can achieve higher accuracy through custom training rather than keyword boosting alone.
2. On-premises and self-hosted deployment: While AssemblyAI now offers self-hosted deployment options for enterprises, Deepgram provides multiple well-documented deployment pathways: standard cloud API, on-premises self-hosted installations using Docker or Kubernetes, and "Deepgram Dedicated" single-tenant environments in preferred cloud regions.
For healthcare, finance, or government applications where audio cannot leave controlled infrastructure, this flexibility is valuable.
3. Unified voice agent API: Building conversational AI with AssemblyAI requires integrating a separate TTS service, as AssemblyAI does not offer text-to-speech (though it does provide an LLM Gateway for transcript analysis).
Deepgram's Voice Agent API provides a single interface combining STT, TTS, and LLM orchestration with native handling of conversational dynamics like barge-in and end-of-thought detection. This reduces both development complexity and cumulative latency from orchestrating separate services.
🏅 NOTE:Speechmatics and Google Cloud Speech-to-Text were also evaluated for this category. While Speechmatics excels at deployment flexibility and Google Cloud offers deep GCP integration, Deepgram provides a strong combination of custom model training, deployment options, and unified voice agent infrastructure for enterprises building production-scale conversational AI.
Deepgram pricing
Deepgram uses usage-based pricing with credits purchased upfront and deducted per second of audio processed. View the full Deepgram pricing page for current rates.
Pay-as-you-go
Speech-to-Text streaming: from $0.0058/min (Nova models)
Speech-to-Text pre-recorded: from $0.0043/min (Nova models)
You need custom model training for specialized terminology: If your domain involves medical terms, legal jargon, or industry-specific vocabulary that generic models consistently misrecognize, Deepgram's custom training delivers accuracy improvements beyond keyword boosting.
Your compliance requirements mandate on-premises deployment: Organizations in healthcare, finance, government, or any sector with data residency requirements will find Deepgram's self-hosted and dedicated deployment options valuable where cloud-only architecture is disqualifying.
You're building real-time voice agents or conversational AI: The unified Voice Agent API eliminates multi-vendor integration complexity and delivers the low latency critical for natural conversational experiences.
Speechmatics — best alternative for unified STT and TTS with flexible deployment
Speechmatics is a Cambridge-based speech recognition company that provides a unified automatic speech recognition (ASR) and text-to-speech (TTS) platform.
Unlike AssemblyAI, which focuses exclusively on speech-to-text and audio intelligence, Speechmatics offers both directions of voice technology in a single platform with deployment flexibility spanning cloud, on-premises, and hybrid options.
Its key features include:
Unified STT and TTS platform: Both speech-to-text and text-to-speech through a single vendor, reducing integration complexity for bidirectional voice applications
55+ languages with accent-agnostic models:Global Language Packs (such as Global English, trained on accents from 40+ countries) that reduce the need for dialect selection
Enterprise security: ISO/IEC 27001:2022, SOC 2 Type II, GDPR and HIPAA compliant
For teams building voice agents, IVR systems, or any application requiring both understanding and generating speech, Speechmatics eliminates the need to integrate and manage separate vendors.
Why choose Speechmatics over AssemblyAI for unified voice platforms
Speechmatics offers capabilities that address specific gaps in AssemblyAI's architecture.
1. Combined STT and TTS eliminates multi-vendor complexity: AssemblyAI is exclusively a speech-to-text provider. Organizations building voice agents, IVR systems, or conversational AI must source text-to-speech from a separate vendor.
Speechmatics offers TTS with sub-150ms latency suitable for voice agent applications, allowing development teams to handle both speech recognition and synthesis through a single API, single vendor relationship, and single billing arrangement.
2. Deployment flexibility beyond cloud While AssemblyAI now offers self-hosted deployment options for enterprises, Speechmatics provides a broader range of deployment pathways: cloud SaaS on Microsoft Azure with multi-region options, Virtual Appliances for on-premises environments, Docker containers for lightweight local processing, and on-device solutions for edge computing.
For healthcare organizations or financial institutions with data residency requirements, this means audio never needs to leave controlled infrastructure.
3. Accent-agnostic global language models Rather than requiring users to select specific dialect variants (American English, British English, etc.), Speechmatics trains comprehensive models on audio from 40+ countries.
Their Global English and Global Spanish packs reduce the need for accent-specific model selection (though you still specify the base language), particularly valuable for contact centers handling international customers.
🏅 NOTE:Google Cloud Speech-to-Text and AWS Transcribe were also evaluated for this category. While Google Cloud offers deep GCP integration and AWS provides seamless Amazon service connectivity, Speechmatics offers a strong combination of TTS capabilities, deployment flexibility, and accent-agnostic models for enterprises needing a holistic voice AI platform.
Speechmatics pricing
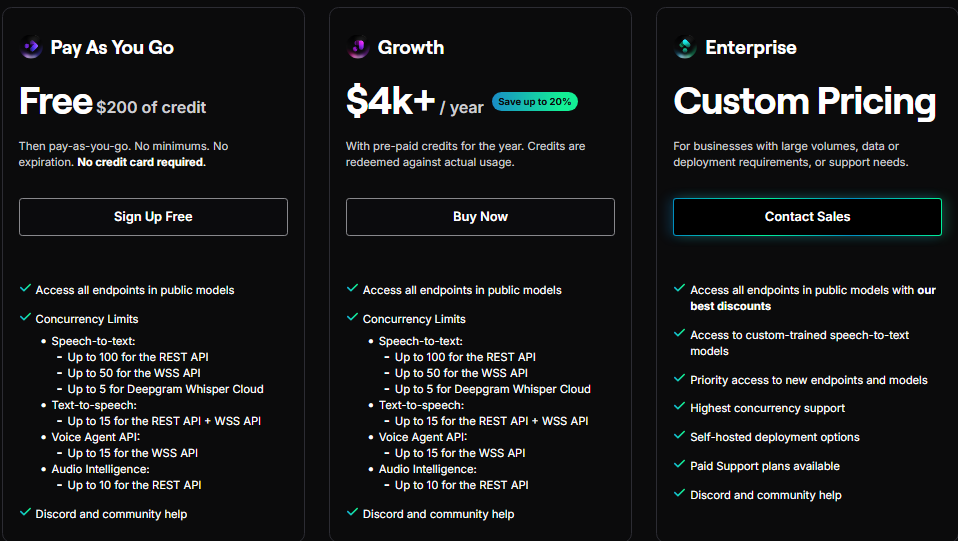
Speechmatics offers tiered pricing with different rates for standard and enhanced accuracy models. View the full Speechmatics pricing page for current rates.
Free tier
480 minutes/month for STT
1 million characters/month for TTS
Limited to 2 concurrent real-time sessions
Pro tier (pay-as-you-go)
Pricing starts from $0.24/hour with rates varying by accuracy level and mode
TTS pricing to be announced (currently in free preview)
20% automatic discount for usage over 500 hours/month
You're building applications that need both STT and TTS: Having transcription and speech synthesis from a single vendor simplifies architecture, reduces vendor management overhead, and ensures consistent behavior across bidirectional voice pipelines.
Your organization has strict data sovereignty requirements: The on-premises Virtual Appliance and container deployment options keep all voice data within your controlled infrastructure.
You handle audio with unpredictable accents: The accent-agnostic Global Language Packs reduce the need for accent-specific model selection (though you still specify the base language), particularly valuable for international contact centers.
Rev — best alternative for human-verified accuracy without developer expertise
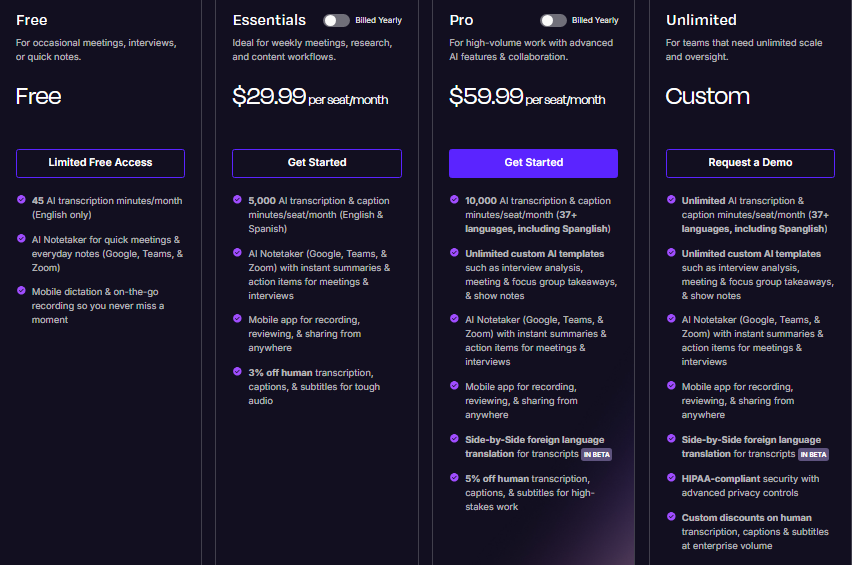
Rev is a hybrid human-AI transcription platform that provides an accessible alternative to AssemblyAI for teams who need high-accuracy transcripts without writing code or managing API integrations. Founded in 2010 with a network of over 70,000 human transcriptionists, Rev offers both AI-powered transcription for speed and human-verified transcription for mission-critical accuracy.
No-code web interface: Upload files directly, paste URLs, or connect Zoom/Teams accounts without any programming
Transparent pay-per-minute pricing: $0.25/minute for AI, $1.99/minute for human transcription
Captioning and subtitle services: FCC/ADA-compliant captions, burned-in captions for social media, and subtitles in 17+ languages
Custom glossary: Submit industry-specific terminology without developer setup
For legal professionals, medical documentation teams, academic researchers, and content creators who need accurate transcripts without technical overhead, Rev provides a fundamentally different approach than API-first services.
Why choose rev over AssemblyAI for human-verified accuracy
Rev addresses needs that AssemblyAI's developer-focused model doesn't serve.
1. Human verification for mission-critical accuracy: Even the best AI models produce errors, particularly with challenging audio, overlapping speakers, or specialized terminology. AssemblyAI users needing near-perfect accuracy must manually review and correct transcripts themselves.
Rev solves this directly with human-verified transcription carrying a 99% accuracy guarantee. For legal depositions, medical dictations, or academic research where errors carry professional consequences, human review provides quality assurance.
2. Zero technical barrier to entry: AssemblyAI is explicitly designed as a "developer-first" platform with REST APIs, SDKs, and technical documentation. Rev's web interface provides drag-and-drop file upload, clear service selection, and completed transcripts delivered to an inbox.
A marketing manager transcribing interviews, a journalist processing sources, or a small business owner documenting meetings doesn't need to write code.
3. Simpler pricing structure: AssemblyAI charges separately for different capabilities: $0.15/hour base plus additional fees for speaker diarization, sentiment analysis, summarization, and other features. Rev's pricing is simpler: flat per-minute rates for core transcription, with optional add-ons (rush delivery, verbatim, timestamps) available at extra cost if needed.
🏅 NOTE:Otter.ai and Descript were also evaluated for this category. While Otter.ai excels at real-time meeting transcription with live collaboration, and Descript is a powerful audio/video editing suite, Rev offers the most seamless path to human-verified accuracy for teams needing professional-grade transcripts without technical expertise.
You need human-verified accuracy without technical overhead: If transcription errors carry professional, legal, or reputational consequences, Rev's 99% human accuracy guarantee provides quality assurance that automated services typically cannot guarantee.
Your team lacks developer resources for API integration: If you don't have developers available to implement and maintain integrations, Rev's web interface lets you start transcribing immediately.
You need captioning and subtitles alongside transcription: If your workflow includes making video content accessible, Rev's integrated services eliminate the need for multiple vendors.
OpenAI Whisper — best alternative for self-hosted free transcription
OpenAI Whisper is an MIT-licensed open-source automatic speech recognition system that provides a compelling alternative for teams prioritizing cost elimination and complete data control over managed convenience.
Released in September 2022 and trained on 680,000 hours of multilingual data, Whisper offers strong robustness across diverse audio conditions without any recurring API fees when self-hosted.
Its key features include:
MIT-licensed open source: Completely free to use, modify, and deploy with no licensing fees
99+ language support: Extensive multilingual training enables transcription across nearly 100 languages with automatic language detection
Self-hosted deployment: Runs entirely on your own infrastructure, keeping all audio data within your environment
Speech translation: Translates speech from any supported language directly into English
Multiple model sizes: Five sizes from "tiny" (39M parameters) to "large-v3" (1.55B parameters) for speed/accuracy tradeoffs
Complete offline operation: Functions identically whether connected to the internet or in air-gapped environments
For early-stage startups, proof-of-concept projects, or organizations with strict data sovereignty requirements, Whisper eliminates recurring API costs while providing production-capable transcription.
Why choose OpenAI Whisper over AssemblyAI for self-hosted transcription
Whisper addresses needs that managed API services may not serve as well.
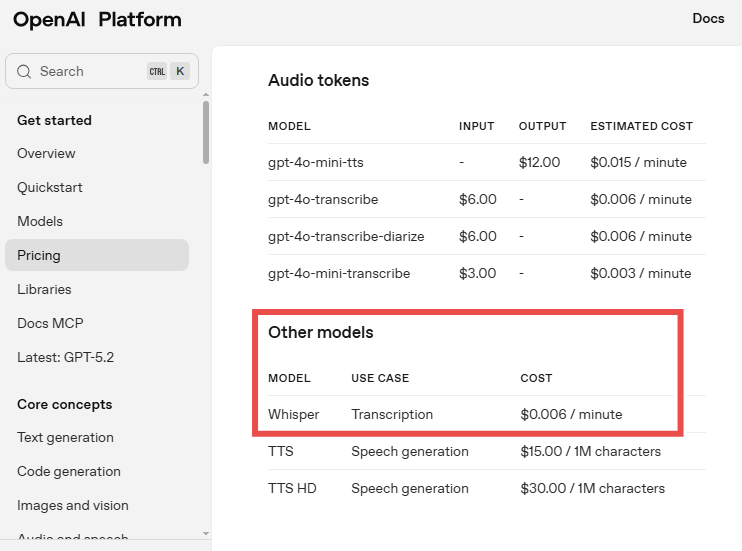
1. Zero recurring API costs: AssemblyAI charges $0.15/hour for their Universal model plus additional fees for features. Whisper eliminates these recurring charges entirely when self-hosted. Organizations processing substantial audio volumes can see significant savings, though this requires investment in computer infrastructure.
For early-stage startups and proof-of-concept projects where unpredictable API bills strain limited budgets, Whisper provides cost predictability.
2. Complete data sovereignty through self-hosting: While AssemblyAI now offers self-hosted deployment options for enterprises, many organizations still use their cloud API, which requires sending audio to AssemblyAI's servers. Some organizations have regulatory requirements or policies prohibiting any third-party audio processing.
Whisper runs entirely on-premises or within your own cloud environment, keeping audio within controlled infrastructure. For healthcare, finance, government, or any scenario where data residency is non-negotiable, this capability is valuable.
3. Open-source flexibility for customization: AssemblyAI's models are proprietary and accessible only through their API or enterprise self-hosted deployments. Whisper's open-source nature enables fine-tuning on custom datasets for domain-specific terminology, experimentation with model modifications, and deep integration into custom pipelines.
sTeams with ML engineering expertise can build differentiated products where ASR is a core component rather than a commodity service.
🏅 NOTE:Mozilla DeepSpeech and Vosk were also evaluated for this category. While DeepSpeech was an early pioneer and Vosk offers lightweight offline recognition, OpenAI Whisper provides the best combination of multilingual accuracy, active development, community ecosystem, and permissive MIT licensing.
OpenAI Whisper pricing
Self-hosted (primary use case)
Completely free under MIT license
Costs determined entirely by compute infrastructure (GPU servers)
Cloud GPU instances vary widely, from under $0.50/hour for entry-level GPUs to $4.00+/hour for high-end options
No per-minute transcription fees regardless of volume
You're an early-stage startup or building a proof-of-concept: Eliminating recurring API costs (though you still pay for compute infrastructure) while validating speech recognition use cases makes Whisper ideal for budget-constrained projects.
Your organization has strict data sovereignty requirements: Self-hosted Whisper keeps all audio processing within your controlled environment, satisfying requirements that cloud APIs cannot meet.
You have ML engineering expertise and want customization flexibility: Fine-tuning on domain-specific data, experimenting with model modifications, or deep pipeline integration reward teams with technical capability, though adapting larger models requires significant computing resources.
Picovoice — best alternative for on-device speech recognition
Picovoice is an end-to-end on-device voice AI platform that provides a complete alternative to cloud-based services for organizations requiring strict privacy, offline operation, or deterministic latency.
Unlike AssemblyAI, which processes audio through cloud servers, Picovoice is primarily designed to run on local hardware (though cloud deployment options are also available), ensuring audio data never leaves the device when used in on-device mode.
Cheetah streaming STT: Real-time transcription processed locally with low latency
Leopard speech-to-text: Batch transcription with speaker diarization (can run on-device or in cloud)
Rhino speech-to-intent: Direct speech-to-intent recognition skipping transcription for 97%+ accuracy
Cross-platform deployment: SDKs for microcontrollers, Raspberry Pi, mobile, web, and desktop
Complete offline operation: Functions identically in air-gapped environments
For organizations building voice-enabled products in regulated industries, embedded systems manufacturers, or any application where data cannot leave the device, Picovoice provides capabilities cloud services architecturally cannot offer.
Why choose Picovoice over AssemblyAI for on-device processing
Picovoice addresses requirements that cloud-based services fundamentally cannot serve.
1. Intrinsic privacy through architecture: AssemblyAI requires sending audio to cloud servers for processing. Even with strong security certifications and data governance policies, the fundamental architecture means audio traverses the network.
Picovoice eliminates this by design: audio never leaves the local device. For healthcare, government, defense, or highly sensitive communications, this architectural approach makes compliance significantly simpler since there's no data transmission to audit or third-party processing agreements required.
2. Zero network latency and deterministic performance: AssemblyAI's real-time transcription is subject to network variability. Latency figures represent medians, not guarantees, with network congestion, geographic distance, and connectivity issues introducing unpredictable delays.
Picovoice's edge-first architecture eliminates network latency entirely, providing consistent response times determined only by local hardware capabilities. For voice-controlled industrial equipment, in-vehicle systems, or interactive voice applications where timing is critical, this determinism is essential.
3. Offline-first without feature degradation:AssemblyAI requires internet connectivity to function; there is no offline fallback. Picovoice operates identically whether connected or completely air-gapped. For industrial IoT deployments, emergency communication systems, or remote locations with limited connectivity, offline capability is a hard requirement rather than a nice-to-have.
🏅 NOTE:Other edge-focused solutions were also evaluated, and Picovoice offers a comprehensive end-to-end platform providing wake words, speech-to-text, text-to-speech, speech-to-intent, and local LLM inference across embedded, mobile, and web platforms in a single integrated ecosystem.
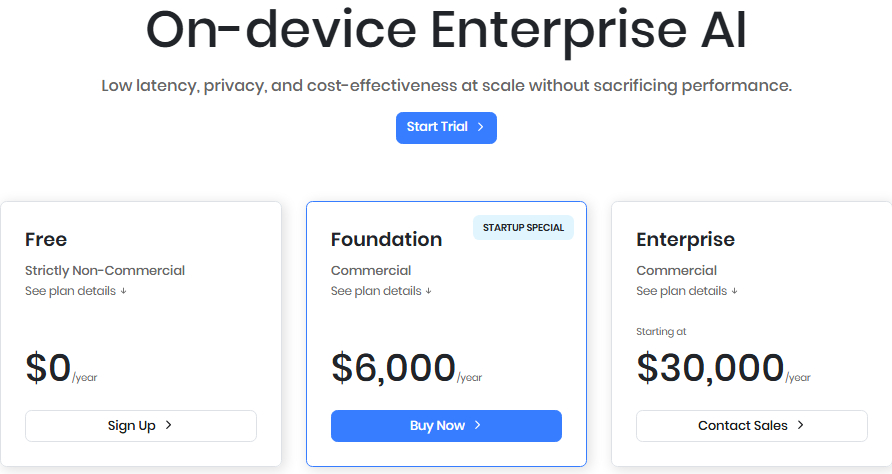
Picovoice pricing
View the full Picovoicepricing page for current rates.
Free plan
$0/year for non-commercial use only
250 minutes/month for Cheetah and Leopard STT
1 monthly active user for wake word and speech-to-intent
1 custom model per month
Foundation plan (startup special)
$6,000/year (annual commitment)
Commercial usage rights
Available to companies <5 years old with <20 employees
You cannot send audio data to any cloud service: Whether due to regulatory requirements, corporate policy, or end-user privacy commitments, Picovoice's on-device architecture ensures audio never leaves the device.
You're building embedded or IoT products with voice interfaces: For hardware manufacturers needing voice capabilities on resource-constrained processors without cloud dependencies, Picovoice's lightweight models run on microcontrollers with limited RAM.
You require offline functionality or deterministic latency: For environments with unreliable connectivity or applications where unpredictable delays are unacceptable, edge processing guarantees consistent performance.
Soniox — best alternative for token-level streaming at competitive pricing
Soniox is a real-time speech AI platform built around a single universal model that handles transcription, translation, and speaker diarization across 60+ languages simultaneously.
Its architecture delivers transcribed words one token at a time with very low latency (targeting sub-200ms), creating near-instantaneous feedback that feels synchronized with natural speech, all at pricing that significantly undercuts most competitors.
Its key features include:
Token-level streaming with very low latency: Delivers transcribed words one token at a time as spoken, providing very fast real-time feedback
Single universal model for 60+ languages: Automatically detects and transcribes any supported language, including seamless code-switching
Built-In translation: Real-time speech translation between any supported language pair, integrated into the transcription API
Competitive pricing: Approximately $0.10/hour for async and $0.12/hour for real-time with transcription, translation, and diarization bundled
Self-learning AI architecture: Unsupervised learning from unlabeled data enables continuous improvement
For developers building latency-sensitive voice applications where response time meaningfully impacts user experience, and where cost efficiency at scale is critical, Soniox provides a compelling combination.
Why choose Soniox over AssemblyAI for fast, affordable streaming
Soniox differentiates itself through architectural choices optimized for speed and cost.
1. Token-level streaming optimized for instantaneous feedback: AssemblyAI's real-time transcription delivers transcripts with approximately 300ms median word emission time. Soniox's architecture streams text token-by-token targeting sub-200ms latency, providing both "provisional" and "final" tokens.
Provisional tokens appear almost immediately, then get confirmed as final once the model has additional context. For voice agent applications where the AI needs to detect when users finish speaking and respond naturally, this faster feedback creates more responsive experiences.
2. Lower pricing with features bundled: AssemblyAI's Universal model costs $0.15/hour, with additional charges for speaker diarization ($0.02/hr), translation ($0.06/hr), and other features. A transcription with multiple add-ons could cost $0.23/hour or more.
Soniox charges approximately $0.10/hour for async and $0.12/hour for real-time with transcription, translation, and diarization included. For high-volume applications, particularly those requiring translation, the savings are substantial.
3. True unified multilingual model: Soniox uses a single universal model that inherently handles all 60+ supported languages without switching between models. This becomes relevant for code-switching scenarios where speakers alternate languages mid-sentence. The model detects and transcribes these switches automatically without requiring language pre-selection.
🏅 NOTE:Deepgram and Rev AI were also evaluated for real-time capabilities. While Deepgram offers competitive speed and Rev AI provides human-in-the-loop options, Soniox delivers a compelling combination of pricing and token-level streaming latency for cost-conscious, latency-critical applications.
Soniox pricing
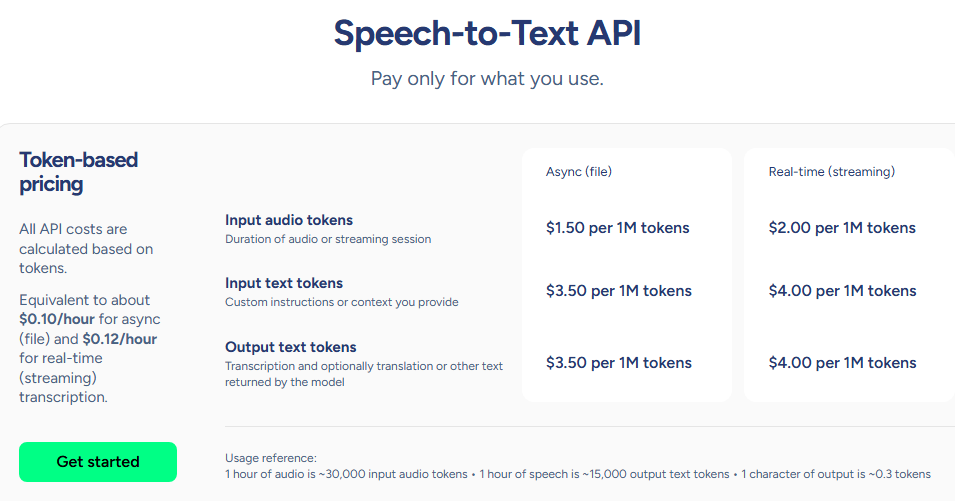
Soniox uses pay-as-you-go, token-based pricing.
Asynchronous transcription
$1.50 per 1 million input audio tokens (~$0.10/hour)
$3.50 per 1 million input text tokens (custom instructions)
$3.50 per 1 million output text tokens
Includes transcription, translation, and diarization
Real-time streaming
$2.00 per 1 million input audio tokens (~$0.12/hour)
You're building latency-critical voice applications: If response time perceptibly impacts user experience, Soniox's token-level streaming architecture delivers very fast feedback.
You need transcription, translation, and diarization at scale without itemized costs: For high-volume multilingual audio processing, Soniox's bundled pricing at $0.10-0.12/hour represents substantial savings over itemized feature pricing.
You want a universal model that handles code-switching automatically: If users frequently switch languages mid-conversation, Soniox's unified model handles this natively without configuration changes.
The final verdict
While AssemblyAI serves as a comprehensive speech AI platform with robust Audio Intelligence and LLM integration through LeMUR, organizations with specific requirements often need specialized solutions that go deeper in particular areas.
Based on this research, here are the best alternatives:
Gladia for real-time multilingual transcription with seamless code-switching across 100+ languages and enterprise-grade data privacy controls
Deepgram for custom model training on proprietary data and flexible deployment options including on-premises
Speechmatics for unified speech-to-text and text-to-speech with cloud, on-premises, and hybrid deployment flexibility
Rev for human-verified 99% accuracy through a no-code interface, ideal for legal, medical, and academic professionals
OpenAI Whisper for self-hosted, free, open-source transcription with complete data sovereignty
Picovoice for on-device processing where audio cannot leave the local environment
Soniox for very fast real-time streaming at competitive pricing
Remember, you don't have to choose between AssemblyAI and these alternatives exclusively.
Many organizations successfully use multiple speech AI providers for different use cases within their tech stack. Consider your specific requirements around language support, deployment constraints, accuracy needs, and cost structure when deciding which solution fits best.
Need to handle multilingual conversations where speakers switch languages naturally? Try Gladia with 10 free hours of transcription each month, or contact their team to discuss enterprise requirements for real-time voice applications at scale.
Contact us
Your request has been registered
A problem occurred while submitting the form.
Read more
Speech-To-Text
Call center voice analytics: use cases, benefits, and how it works
Speech-To-Text
Customer sentiment analysis: methods, tools, and what voice data adds
Speech-To-Text
Named Entity Recognition from call transcripts: improving precision
From audio to knowledge
Subscribe to receive latest news, product updates and curated AI content.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.