Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Gladia CLI: transcribe audio from your terminal in one command
You have a recording on your desk and you need the text. Forty minutes later, you're reading API docs about polling intervals, writing an upload handler, and you still don't have the transcript. That gap between "I have audio" and "I have text” is filled with code nobody wants to write. Today we're shipping the shortcut.
Call center transcription software: what enterprises should look for in 2026
TL;DR: Most contact centers evaluate transcription software using clean-audio lab benchmarks, then watch QA automation break down when BPO (Business Process Outsourcing) agents switch languages mid-call or phone-line noise degrades the signal. In 2026, the criteria that matter are real-world multilingual WER, all-inclusive per-hour pricing, and data sovereignty that holds up under GDPR and HIPAA audit. For enterprise teams, the highest-ROI evaluation step is testing on real BPO call samples rather than vendor demo audio, and asking every shortlisted provider for an all-in per-hour price with diarization, sentiment, and entity extraction enabled.
PII redaction for call recordings: how ingestion-level redaction keeps calls PCI compliant
TL;DR: Legacy pause-and-resume systems don't remove agents, local desktops, or telephony infrastructure from PCI DSS audit scope. Automated, ingestion-level PII redaction scrubs sensitive data before it reaches any database. By removing cardholder data at the ingestion layer, contact center platforms using automated redaction can potentially reduce audit complexity, cut agent handle time (AHT), and protect downstream CRM and LLM pipelines from corrupt data. The accuracy floor for reliable entity detection in PCI audits is significantly higher than for standard QA transcription, making STT model selection a compliance decision as much as a product one.
Building real-time multilingual ASR with code-switching
Published on Jun 1, 2026
by Bruno Hays
When a speaker switches languages, traditional models keep outputting the previous one for several hundred milliseconds before catching up, producing garbled text and inaccurate timestamps. The obvious fix is a large multilingual model. But those are expensive to run, awkward to deploy on-device, and still stumble on fast switches.
Bruno Hays, a Lead ML Speech Engineer at Gladia went the other way. In his original research, instead of one heavy model that tries to know every language at once, he built a lightweight, modular ensemble that routes between small, specialized models and runs efficiently on standard CPUs.
Here's how the system works, how it stacks up against leading commercial and open-source alternatives, and where it still hits a wall. The code is fully open source.
TL;DR
Real-time multilingual transcription lags on code-switching: streaming models keep outputting the old language for a few hundred milliseconds, producing garbled text and bad timestamps.
The fix is a lightweight, CPU-friendly ensemble that routes between small (~100M param) monolingual streaming Zipformer models instead of one heavy multilingual model.
On inter-utterance code-switching, it hit ~13% WER, beating Deepgram Nova-3 (~14%) and the much larger local Voxtral-Mini-4B (~21%).
On intra-utterance switching, VAD can't segment switches fast enough and WER climbs to ~41% behind cloud APIs like ElevenLabs (~26%).
Architecture: a modular ensemble instead of one monolithic model
The core idea is simple: rather than asking one model to be fluent in every language at once, hand each language to a specialist and add a thin layer of logic to decide who should be listening.
The pipeline replaces high-parameter monolithic models with a modular ecosystem of three specialized components:
VAD (Voice Activity Detection): Driven by Silero V6 to identify speech boundaries with minimal latency.
ASR (Automatic Speech Recognition): Streaming Zipformer models served via the sherpa-onnx framework. At only ~100M parameters, these models are purpose-built for efficient, CPU-bound transcription.
LID (Language Identification): Powered by Speechbrain's lang-id-voxlingua107-ecapa for linguistic detection across up to 107 languages.
The asynchronous rollback pipeline
To minimize language lag during transitions, we implemented an Asynchronous Rollback Pipeline. It works in three steps:
Immediate transcription: The system transcribes instantly using the currently active monolingual ASR engine.
Asynchronous monitoring: Following each speech boundary identified by the VAD, the system triggers LID checks on expanding audio windows in the background.
The rollback trigger: If the LID detects a language switch with high confidence, the system switches the active ASR stream to the new language model, rolls back the transcript to the exact segment boundary where the switch occurred, and re-infers the buffered audio for that specific range.
The corrected text is then injected into the stream. The user only sees the wrong-language artifacts briefly in partials, while the final transcripts feature clean language boundaries.
How we evaluated the pipeline
Speech recognition performance isn't a single number — it shifts with context, speaker, and how messy the audio gets. So rather than report one headline score, we stress-tested the pipeline across three datasets that get progressively harder, each targeting a different transcription scenario.
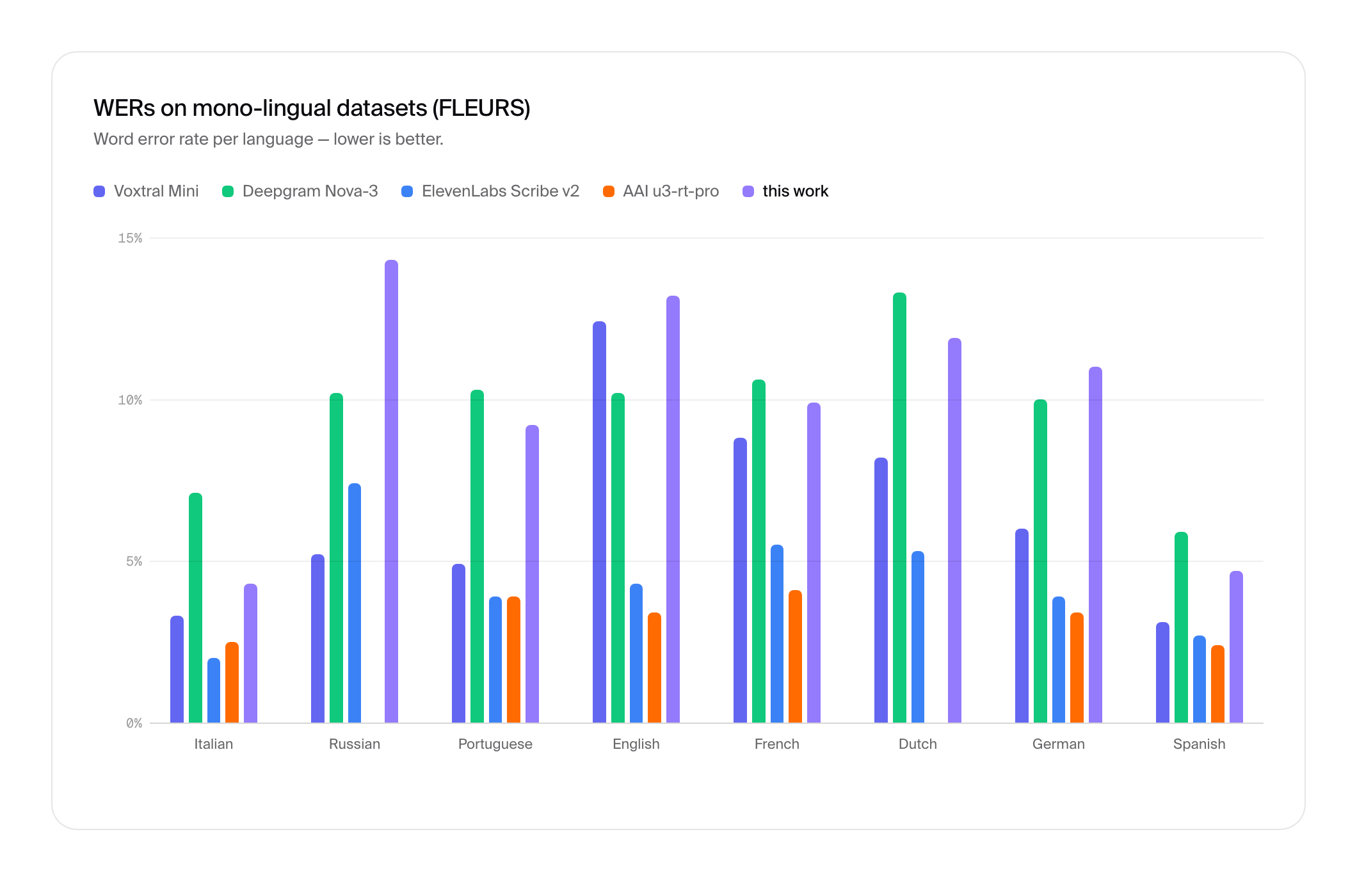
What it measures: FLEURS contains high-quality, single-language utterances. We used it to measure the baseline performance of the underlying streaming models. The results show that performance degradation on monolingual datasets can be observed for all providers when moving away from native monolingual setups.
What it measures: This dataset was built by mixing samples from eight major languages (en, fr, es, de, ru, it, pt, nl) chained sequentially. It measures inter-utterance code-switching, where a speaker switches languages between sentences or distinct speech boundaries.
3. Bangor-Miami Corpus (intra-utterance code-switching)
What it measures: This conversational dataset captures informal speech among bilingual speakers. It measures intra-utterance code-switching, where people randomly mix words from different languages inside the same sentence (e.g., Spanglish). There are no acoustic pauses between language flips here.
Benchmarks and models used
For our solution, we used available open-source streaming Zipformer models with a 640ms chunk size:
We compared our results against Deepgram's Nova-3 model in multilingual mode, ElevenLabs Scribe v2, MistralAI's Voxtral-Mini-4B-Realtime (with 480ms target streaming delay), and AssemblyAI's u3-rt-pro.
AssemblyAI's u3-rt-pro does not support Dutch and Russian, so we did not measure its accuracy on any dataset comprising these languages.
When language shifts happen at natural speech boundaries, this architecture performs well. Our routing logic achieved a ~13% Word Error Rate (WER), outperforming every other solution, including paid solutions like Deepgram Nova-3 (~14%) and beating the larger, local Voxtral-Mini-4B (~21%).
Intra-utterance code-switching (Miami Corpus)
Here, the limitations of a VAD-reliant architecture become apparent. Because the language switches happen faster than a VAD speech boundary can segment them, the rollback mechanism is not triggered effectively.
Our system's WER degraded to ~41%.
While it was outperformed by cloud APIs like ElevenLabs (~26%) and Deepgram (~29%), it still outperformed the local Voxtral-Mini-4B, which collapsed with a ~76% WER.
Detailed WER
WER Benchmark Comparison
FLEURS dataset
Voxtral Mini
Deepgram Nova-3
ElevenLabs Scribe v2
AAI u3-rt-pro
This work
Italian
3.30%
7.10%
2.00%
2.50%
4.30%
Russian
5.20%
10.20%
7.40%
—
14.30%
Portuguese
4.90%
10.30%
3.90%
3.90%
9.20%
English
12.40%
10.20%
4.30%
3.40%
13.20%
French
8.80%
10.60%
5.50%
4.10%
9.90%
Dutch
8.20%
13.30%
5.30%
—
11.90%
German
6.00%
10.00%
3.90%
3.40%
11.00%
Spanish
3.10%
5.90%
2.70%
2.40%
4.70%
Code-switch
21.30%
14.30%
13.60%
—
13.20%
Miami
76.30%
28.60%
26.50%
34.00%
41.00%
Average
6.50%
9.70%
4.40%
3.30%
9.80%
Summarized across the three evaluation scenarios:
Code-Switch Benchmark Comparison
Dataset
Voxtral Mini
Deepgram Nova-3
ElevenLabs Scribe v2
AAI u3-rt-pro
This work
FLEURS accuracy (averaged)
6.50%
9.70%
4.40%
—
9.80%
Simulated inter-utterance code-switch (FLEURS)
21.30%
14.30%
13.60%
—
13.20%
Real-life intra-utterance code-switch (Miami)
76.30%
28.60%
26.50%
34.00%
41.00%
Limitations and future outlook
1. The intra-utterance gap: Relying on VAD segment boundaries means rapid, mid-sentence word mixing slips through. In real life, only a few such blends exist, like Spanglish or Singlish (Singapore). A promising solution is to treat the blend as its own "new language" and use a dedicated bilingual model for that stream.
2. Monolingual constraints: The overall accuracy is bounded by the maturity of the underlying open-source Zipformer models available for each language.
The case for small, specialized models
Handling a large number of languages within a single model requires significant knowledge, which translates to higher parameter counts. For local, on-device ASR, trying to build a single model that does everything can be inefficient.
The results of this implementation suggest that the future of local multilingual ASR could lie in orchestrating small, hyper-specialized models via an intelligent routing layer. Keeping the individual models small allows for a lightweight system that deals with inter-utterance code-switching better than competing open-source alternatives, despite their larger size.
What is code-switching in automatic speech recognition?
Code-switching is when a speaker alternates between two or more languages. In real-time ASR it causes "language lag" — streaming systems keep outputting the previous language for several hundred milliseconds after a switch, producing garbled text and inaccurate code-switching timestamps.
What's the difference between inter-utterance and intra-utterance code-switching?
Inter-utterance code-switching is when a speaker switches languages between sentences or distinct speech boundaries. Intra-utterance code-switching is when words from different languages are mixed inside the same sentence (e.g., Spanglish), with no acoustic pauses between the language flips.
How does the Asynchronous Rollback Pipeline reduce language lag?
It transcribes immediately using the active monolingual ASR engine, runs language-identification checks on expanding audio windows in the background after each VAD speech boundary, and — when it detects a high-confidence switch — swaps to the new language model, rolls back the transcript to the segment boundary, and re-infers the buffered audio. Users only see wrong-language artifacts briefly in partials; final transcripts have clean boundaries.
Can small, specialized ASR models outperform large multilingual models?
On inter-utterance code-switching, yes. The small-model ensemble reached ~13% WER, outperforming Deepgram Nova-3 (~14%) and the larger local Voxtral-Mini-4B (~21%). On intra-utterance code-switching (Miami), it reached ~41% WER — behind cloud APIs but still ahead of Voxtral's ~76%.
What are the limitations of a VAD-based code-switching pipeline?
Because it relies on VAD segment boundaries, rapid mid-sentence word mixing (such as Spanglish or Singlish) slips through, since switches happen faster than a VAD boundary can segment them. Accuracy is also bounded by the maturity of the available open-source Zipformer models for each language.
Contact us
Your request has been registered
A problem occurred while submitting the form.
Read more
Product News
Gladia CLI: transcribe audio from your terminal in one command
Speech-To-Text
Call center transcription software: what enterprises should look for in 2026
Speech-To-Text
PII redaction for call recordings: how ingestion-level redaction keeps calls PCI compliant
From audio to knowledge
Subscribe to receive latest news, product updates and curated AI content.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.






















.png)